

机械智造
1 引言
具身智能工业机器人(EIIR:embodied intelligent industrial robotics)主要关注能够在工业环境中独立感知、决策和执行任务的工业代理。 它是具身智能(EI:embodied intelligent)和工业机器人(industrial robots)的结合。 随着制造业向智能化和数字化方向发展,智能制造通常被视为该行业的首要目标,而具身智能是实现这一目标的最重要的方法。
多模态大型模型(MLM)的出现使具身智能机器人(EIR:embodied intelligent robotics)拥有更强的感知、决策和任务执行闭环能力[1]。 这一进步使 EIR 能够超越传统的教学和编程方法,转向由自然语言指导的自主任务规划和执行;因此,现在可以实现任务级的灵活性。 然而,目前的大多数研究都集中在将具身智能应用于日常生活场景,例如家庭服务和社交互动[2]。 很少有研究探索其在工业应用中的潜力,例如组装、焊接和材料处理[3]。 本文系统地介绍具身智能在工业机器人领域的技术框架和应用潜力。 重点放在实际的 EIIR 实施路径和 EIIR 支持技术的最新进展的回顾上。 希望这篇综述能为有兴趣将具身智能引入工业实践的研究人员和工程师提供前瞻性的见解和有用的参考,从而帮助该概念在实际应用中发挥作用。
2 EIIR 定义和框架
2.1 工业机器人:从自动化到具身智能
自1960年代工业机器人(iRobot)问世以来,出现了许多分类方法[8-10]。 如图1所示,工业机器人根据主流技术和灵活性的发展趋势,大致可以分为三个时代:
自动化时代(Automation era): 在工业机器人的早期阶段,iRobots 的主要优势是其可编程性。 研究重点是机器人本体及其核心部件的开发。 这些机器人使用硬编码指令执行具有预定义动作的固定任务。 虽然它们非常高效和准确,但它们的灵活性非常有限。
感知智能时代(Perception intelligence era): 随着传感器、机器视觉和深度学习的进步,iRobots 获得了强大的感知和视觉伺服能力,从而实现了更高程度的技能水平灵活性。 例如,由于视觉感知能力的提高,机器人可以管理在装卸任务期间未精确定位的零件。 但是,它们在任务级别仍然缺乏灵活性。
具身智能时代(Embodied intelligence era): LLM、MLM、世界模型和知识图谱等其他技术的快速发展,正在将 iRobots带入一个新的阶段——具身智能时代。 在这个时代,单个 iRobot 将成为能够在其环境中进行感知、自主决策和执行的工业代理,就像人类工人一样。 iRobot 将能够完成各种任务,例如装载、卸载、搬运、码垛和组装。 因此,它们将展示真正的任务级灵活性,即工业场景中的通用智能。
每个工业机器人时代都建立在前一个时代开发的技术之上。 笔者认为,iRobots现在正在进入具身智能时代的早期阶段。 一个关键的未来趋势是将具身智能与工业机器人相结合,形成EIIR,这将应用于不同的工业系统。
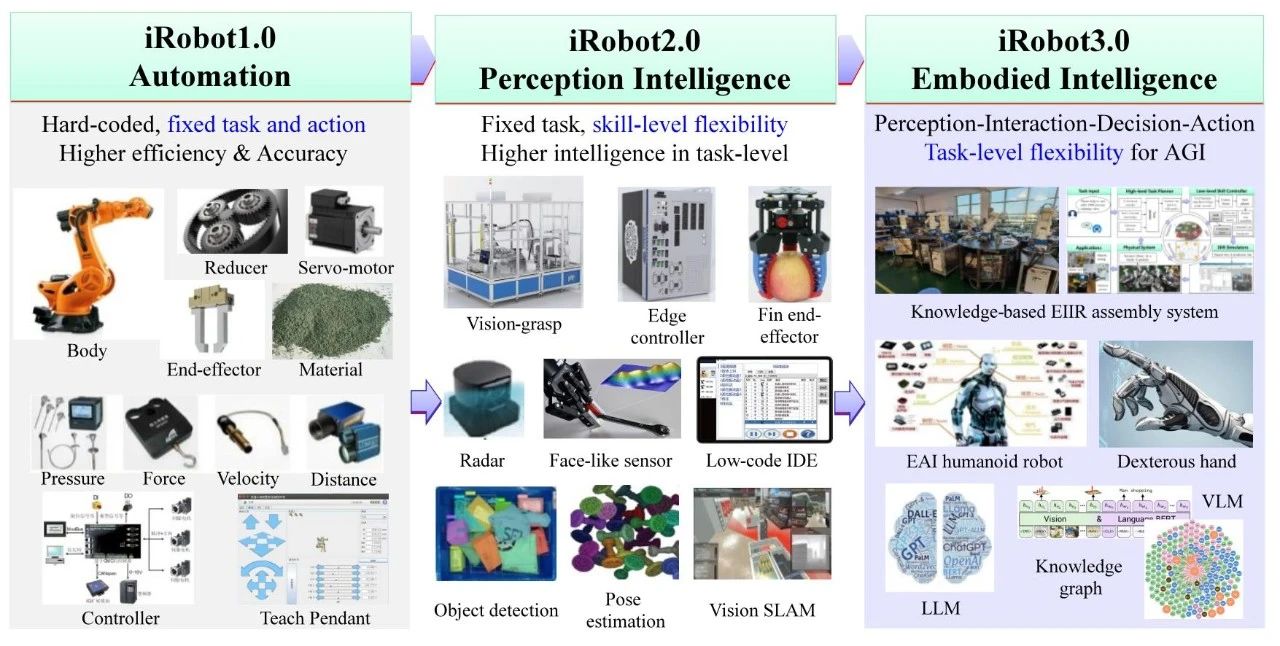
图1.工业机器人的三个时代
人工智能(AI)、具身智能机器人(EIR)和具身智能工业机器人(EIIR)之间的关系,如图2所示。AI主要由三个技术流派组成:符号主义、联结主义和行为主义。 EI代表了行为主义的前沿。 它主要研究能够感知、做出决策并与环境交互的代理。 它强调代理必须通过环境交互来证明,而不仅仅是通过符号计算;因此,它与图灵在1950年提出的具身图灵测试[12]一致。 EI 包含两个主要类别: 虚拟代理和物理代理。 在物理代理中,机器人是最合适的载体;因此,它们导致了EIR 的出现。 EIR 使用多模态传感器来感知其环境,使用认知模型实现动态决策,并控制与物体交互并能够完成复杂任务的物理执行器。 EIR 的形式在很大程度上取决于其应用领域;现有的 EIR 表格包括类人机器人、四足机器人、移动机器人、工业机器人和服务机器人。 在这个框架内,工业机器人代表了一种专为工业应用设计的特定 EIR 形式;此表单称为EIIR。 因此,EIIR 专注于具备独立感知、决策和执行能力的工业机器人,这些能力是为工业环境、数据和任务量身定制的。 与 EI 一样,工业具身智能也可以分为两类: 虚拟和物理。 虚拟工业代理可以存在于机器人或生产线模拟器中( 将在第 6 节中讨论)。 EIIR 专注于典型的物理工业代理,以实现任务级的灵活性。
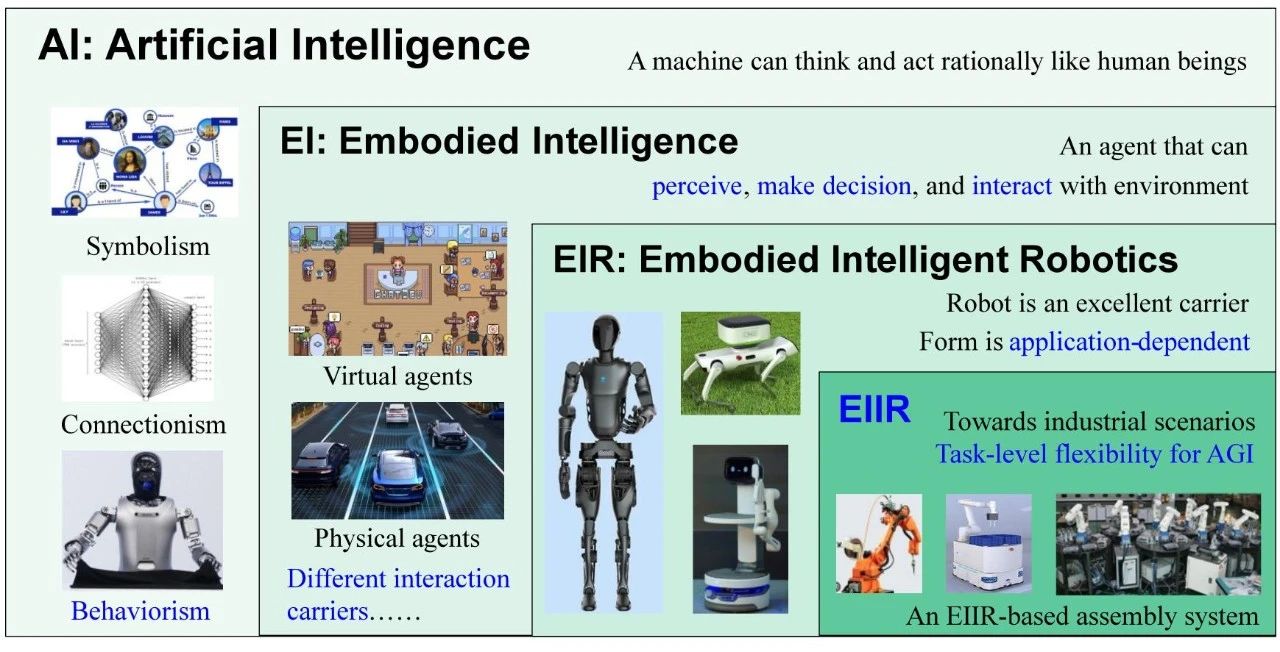
图2.AI、EI、EIR 和 EIIR 之间的关系
2.2 EIIR框架概述
现有的 EIR 框架大致可分为两类: 分层架构和端到端架构。 分层架构是主流,如下图3人形机器人,其双系统设计灵感来自大脑和小脑。 分层架构通常由两个主要层组成:高级规划器和低级控制器[1]。 高级规划者使用 MLM 来处理文本( 例如,“ 带一个苹果到我的房间” )和视觉输入(例如图像标题或场景图)。 然后,它使用语义推理将抽象任务分解为一系列可执行的子任务( 例如,去厨房→找到冰箱→打开冰箱→......低级控制器管理任务执行。它使用具身感知模型( 例如,可用于估计苹果的位置和方向)和物理交互模型( 例如,可用于生成机械手动作)来执行每个子任务,并由实时传感器反馈指导。 模拟器也可以集成到此框架中,以便在不同的虚拟环境中训练和测试代理。 这种虚实集成方法比物理试错方法更便宜,并且它通过来自环境交互的持续反馈来支持系统自我改进。
端到端架构将视觉、语言和行动集成到一个模型中,称为视觉-语言-行动(VLA)模型。 这样的模型用于直接对包括感知、决策和行动在内的完整闭环进行建模。 利用这种方法的代表性工作包括 Google 的 RT 系列 [14,15] 和 OpenVLA [16]。 此体系结构通常由三个核心模块组成: 多模态输入处理模块、跨模态融合模块和动作解码模块。 首先,VLA模型获得三种类型的输入: 视觉数据( 图像或视频)、语言文本和动作数据( 例如过去的运动轨迹)。 接下来,使用交叉注意力机制,该模型在共享语义空间中对齐视觉特征、语言嵌入和动作表示。 这种对齐使模型能够理解不同模态之间的关系并有效地组合它们的信息。 最后,组合的多模态表示被传递给动作解码器,该解码器生成连续的控制信号( 例如,机械臂的关节角度)或离散的动作序列( 例如,导航路径或作步骤)。
然而,由于多种原因,将上述 EIR 框架应用于工业场景具有挑战性。 首先,尽管大型模型具有一般知识,但它们缺乏对工业环境的深入语义理解。 例如,当代理被分配一个阀门装配任务时,它很难生成符合工程约束的任务分解计划,因为它没有内化关键的工业知识,例如零件拓扑、装配程序或扭矩参数。 其次,现有框架生成的大多数动作指令都是根据机器人作系统( ROS)设计的。 相比之下,工业环境通常涉及异构控制系统的混合,这些系统可能包括机器人、由可编程逻辑控制器(PLC)驱动的传送带和伺服压力机。 这种差异阻碍了跨多个工业设备实现协调控制。 最后,现有的机器人模拟器通常侧重于单个机器人的仿真。 然而,工业生产线需要结合机械、电气、液压和控制域的系统级仿真。 例如,在汽车焊缝线的虚拟调试期间,必须模拟机器人焊接臂、PLC控制夹具和视觉检查系统的协调作。 目前的机器人模拟器缺乏跨域数字孪生的重建能力;因此,他们很难支持工业代理的训练数据生成和虚拟调试。
为了应对这些挑战,本研究期间开发了一个知识驱动的 EIIR 技术框架。 如图 4 所示。 它根据工业场景、数据和任务的需求量身定制。 它由五个部分组成: 世界模型、高级任务规划器、低级技能控制器、模拟器和物理系统。 世界模型是代理的主要知识源,是该框架的中心。 它提供一般知识、工作环境知识和操作对象知识。 常识为自然语言任务的解释提供了LLM 的语义基础。 工作环境知识采用生产线语义图的形式,其中设备方向、可作边界和其他环境约束被动态标记。 操作对象知识采用特定领域的知识图谱的形式,在结构上存储产品流程和参数,从而使规划者能够生成符合工业规范的子任务序列。
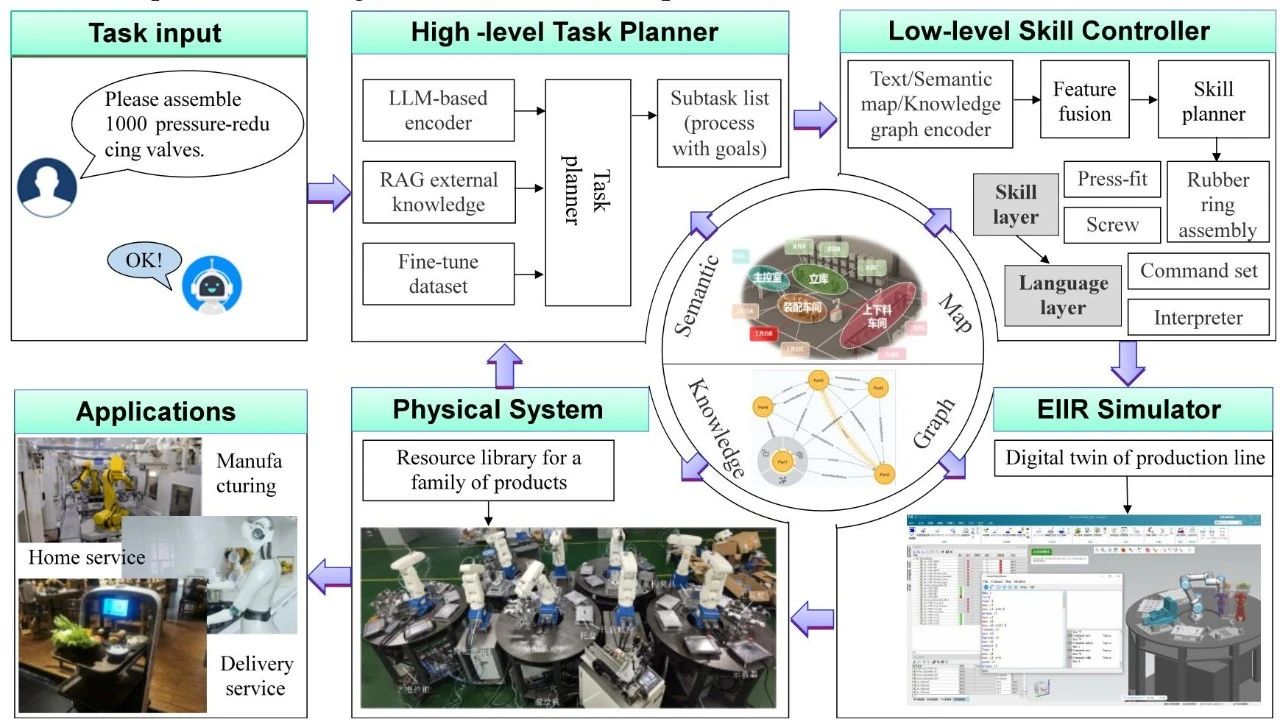
图4.知识驱动的 EIIR 技术框架
有了这个 EIIR 框架,当用户下达“ 请组装 1000 个减压阀” 之类的命令时,高级任务规划器通过基于 LLM 的编码器解析语义,并整合外部知识将任务拆解成一系列子任务。 接下来,低级技能控制器将抽象的子任务映射到物理作中,技能层可以调用库中预定义的技能,并在语言层将其转换为与设备无关的标准化指令。 然后,使用解释器将这些指令动态转换为各种目标控制器的协议指令,从而驱动设备执行任务。 然后,EIIR 模拟器构建生产线级数字孪生,以在虚拟环境中生成制造条件数据集。 它还通过使用中间件( 如 ROS 或 OPC UA)来验证生成的指令的正确性,从而实现包括机器人和 PLC 在内的跨平台协同仿真。 最后,在物理系统中完成虚实生产线作。
本文接下来的四个部分重点介绍世界模型,即高级任务规划器、低级技能控制器,以及这个知识驱动的EIIR框架的EIIR模拟器。这四个部分总结了现有的相关技术,并解释了这些组件如何协同工作。 因此,它们为负责选择合适的EIIR技术的学者或工程师提供了参考。
3 工业场景的世界模型

非 LLM 方法通常使用图神经网络(GNN)来组合各种 3D 语义场景中的先前特征以进行特征提取。 最后,功能是用于预测每个对象的语义标签以及对象之间的语义关系。 Wald 等人[22] 提出了一种从场景的点云中获取语义图的学习方法。 该方法基于 PointNet,使用图卷积网络(GCN)生成语义图。 这些学者还引入了一个基于这项任务的半自动数据集,其中包含具有足够语义信息的语义图谱。 这项工作和数据集为语义图生成的发展奠定了良好的基础。 为了满足机器人应用场景的增量化和实时性要求,Wu et al.[23]提出了一种称为 SceneGraphFusion 的方法,其中使用 RGB-D 视频序列来增量构建语义图。 该方法使用 GNN 从原始场景的组件中聚合 PointNet特征。 此外,作者还提出了一种新的注意力机制,可以在存在不完整数据和缺失图数据的情况下,对场景进行有效的逐帧重建。 随后,为了解决语义映射构建过程中密集点云所需的高计算能力,他们优化了上述算法并提出了 MonoSSG[24]。 该算法基于稀疏点云、场景图像等多模态特征,使用多视图和集合特征聚合 GNN 并预测语义图。 该方法在保持良好准确性的同时,显著提高了语义图构建速度。 对于结构复杂的室内场景和有行人的动态场景,Rosinol 等[25]提出了一种构建有向 3D 动态语义图的方法。 映射中的节点表示场景中的实体( 例如对象、墙壁和房间),而边表示节点之间的关系( 例如包含和邻近)。 该地图还包括移动代理( 例如人类和机器人)和可作信息( 例如各种抽象级别的时空关系和拓扑关系),以支持规划和决策。 为了解决实时机器人感知过程中的语义图构建问题,Hughes 等[26]提出了 Hydra,这是一种实时语义图构建算法。 欧几里得有符号距离场(ESDF)用于重建机器人感知的场景。 此外,ESDF 构建的语义图被划分为多个分层房间,从而可以构建多级语义图。 该方法还对 map构建了 loopback 检测和全局优化算法;该算法可以为机器人实现实时高效的语义图构建。 一般来说,非 LLM 语义图构建算法通常使用点云和图像作为特征输入。 模型架构使用 GNN 作为特征聚合的中间框架,根据空间拓扑结构组织语义图构建。 该类算法推理速度快,适合端到端部署,能够满足动态场景构建需求;但是,它的语义特征维度是有限的。 因此,使用这类算法时,很难获取场景中的复杂语义信息。
LLM 的发展为语义的提取和生成带来了新的研究视角。 与 vision 集成的 MLM 可以感知和汇总场景图像中的多种语义信息。 此外,大模型可以根据汇总的语义信息进一步进行检索、推理和规划任务;因此,可以显著增强对实际场景的语义感知能力。 Chang et al.[27] 提出了一种开放的面向词汇的语义图构建推理框架,该框架以自然语言文本输出的形式获取各种实体之间的联系。 与传统的基于语义的对象定位方法不同,该框架支持上下文感知实体定位;因此,它允许基于实置的查询,例如“ 在厨房桌子上拿起杯子” 或“ 导航到某人坐的沙发” 。 与现有的语义图研究不同,这种方法支持自由文本输入和开放词汇查询。
为了解决语义图的单模态标签问题,Jatavallabhula 等[28] 提出了一种多模态语义图构建方法,称为 Conceptfusion。 该方法能够解决现有语义图概念推理的闭集限制,将语义检索拓展到自然语义的开放集。 此外,该方法构建的语义图谱包含多模态语义属性。 该方法可以使用语言、图像、音频和 3D 几何输入从地图中检索对象。 Conceptfusion 使用基础模型的开放集功能,该功能在 Internet 规模数据上进行了预训练,以推断不同模式的概念。 这种方法具有零喷射特性,不需要任何额外的训练或微调,可以更好地保留长尾概念;因此,它优于监督方法。
为了解决与使用 RGB-D 视频序列构建大型场景语义图相关的复杂多样的困难,Gu 等人[29]提出了一种利用 LLM的方法。 该方法采用 2D 检测和分割模型,通过多视图RGBD 序列将检测结果的输出集成到 3D 中。 这种方法还具有零镜头特性,无需收集大量 3D 数据集或微调模型即可构建语义图。 实验表明,这种方法可以支持用户输入的及时分配,以及整合对空间和语义概念的理解( 这是一项下游规划任务)的复杂推理。
为了解决多层建筑导航中极其复杂的空间描述问题,Werby 等[30]提出了一种语义地图构建方法,称为 HOV-SG,用于多层和多房间导航任务。 首先,使用开放词汇视觉基础模型构建 3D开放词汇语义图。 然后,在地图上划分楼层和房间,并确定房间名称和类型。 最后,利用结果构建三维多级地图。 该方法的主要特点是能够表示多层建筑,并为建筑中的机器人提供语义连接。 该方法在用于长距离、多层建筑导航任务时产生了非常好的实验结果。
户外场景语义信息的复杂性和多样性是导致语义图构建技术相关的应用程序限制的主要原因。为了解决这个问题,Strader et al.[31] 提出了一种基于本体的室内和室外通用语义图构建技术。 首先,作者提出了一种建立空间本体的方法,并定义了与室内和室外机器人作相关的概念和关系。 特别是,作者使用 LLM 构建了一个基本的语义本体,这大大减少了手动注释的工作量。 接下来,作者使用逻辑张量网络(LTN)构建了基于空间本体的语义图。 添加到 LLM中的逻辑规则和公理在训练期间提供了额外的监控信号,从而减少了对标记数据的需求。 这种方法提供了更准确的预测,它甚至预测了训练过程中没有看到的概念。
在语义映射构建过程中,LLM 通过执行各种任务( 例如语义提取、推理和分类)来充当语义相关的运算符;然而,现有的工作更侧重于语义提取和基于视觉感知的 3D 重建。 对于机器人来说,理解抽象的空间语义是感知物理世界的重要前提。 LLM 构建了机器人可以用来感知物理世界的直观工具;因此,它们能够对机器人进行深入的语义理解和作。 语义映射是此类作中的中间表达式和元素。
3.2 知识图谱
知识图谱是 Google 在2012 年推出的一种表示方法[32],它使用图数据库来组织和存储信息,以实现高效的检索和推理。 使代理能够理解工业环境中的操作对象知识是EIIR 的一个关键挑战。 随着制造业转向更大的灵活性和定制化,这一挑战变得更加严峻,因为它需要 EIIR 管理涉及多种产品类型和小批量的混合生产线生产。 因为它们代表了操作对象知识的认知核心,所以知识图谱实现了关键功能。 通过结构集成产品参数、制造工艺和设备资源,它们实现了可解释的过程推理,从而支持动态任务规划,可以根据传感器反馈和生产变化实时适应。
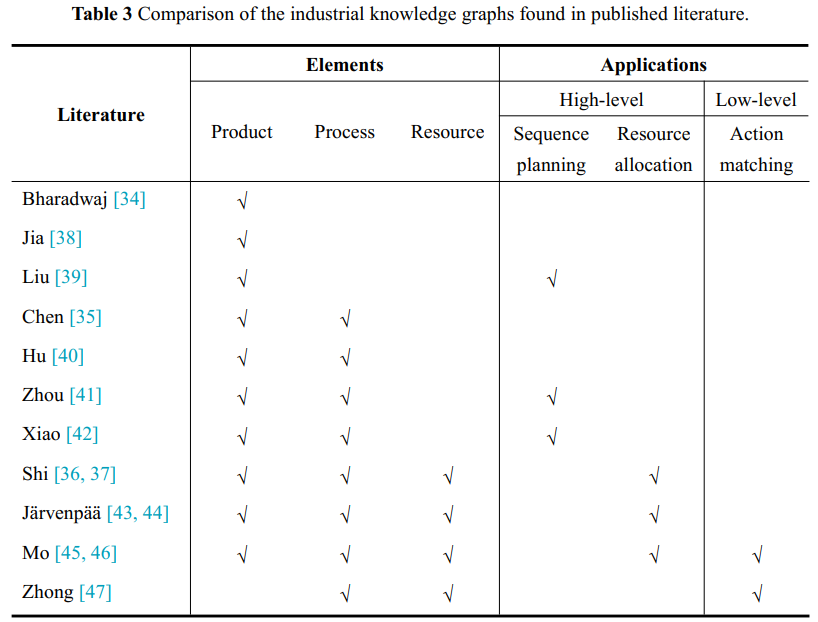
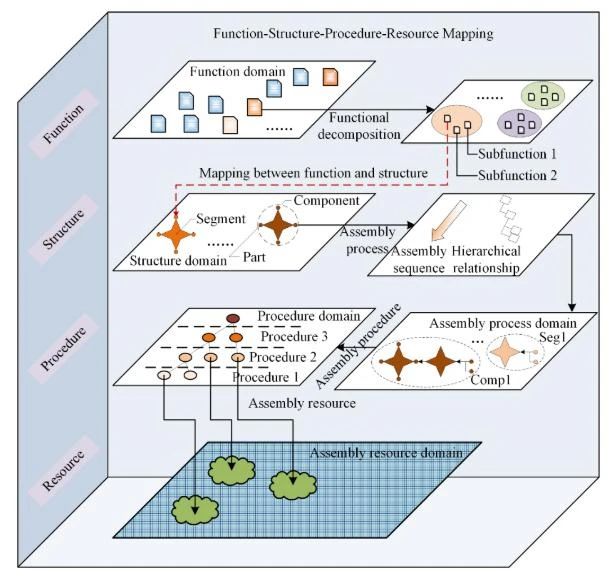
使用工业知识图谱,EI 驱动的工业系统可以支持高级和低级决策任务,包括序列规划、资源选择和分配以及动作匹配。 首先,使用嵌入在产品和流程知识图谱中的知识、规则和算法进行序列规划。 例如,Liu[39] 开发了一个三层装配信息模型,该模型表示产品数据并支持根据实例化知识进行规划。 其次,为了提高资源的可重用性,Järvenpää[43,44] 定义了一个概念性资源结构。 此结构集成了产品、流程和资源信息,从而实现了流程-资源匹配。 同样,为了响应不断变化的需求,Mo[45,46] 构建了一个知识图谱,该图谱使用来自 OmniFactory 的真实数据来支持资源选择和系统重新配置。 最后,知识图谱还支持执行级别的作匹配。 Zhong[47] 将机器人技能存储在知识图谱中,从而允许系统将合适的技能与输入任务相匹配。 然后将这些技能分解为基本作以供执行。
4 高级任务规划器
高级任务规划器位于 EIIR 框架的顶层。 它接收用户用自然语言描述的任务,并将其转换为子任务,以指导机器人的具体动作[48]。 这个过程使机器人能够理解自然语言,增强了非专业操作员控制机器人的便利性。 在本节中,首先介绍了基于一般知识的一般任务规划技术。 接下来,介绍了工业场景的任务规划技术及其规范和约束。
4.1 一般任务规划
一般任务规划使用一般知识来管理非结构化环境中的任务,例如购物中心和餐馆。 它的目标是通过自然语言输入将任务划分为子任务序列。 通过结合视觉感知和多模态信息处理,机器人可以适应环境变化并实时完成任务。 例如,如果给出命令“ 请帮我拿一个苹果” ,机器人可以将任务拆分为以下子任务: “ 找到苹果” 、“ 前往苹果的位置” 、“ 抓住苹果” 、“ 导航到餐桌” 和“ 将苹果放在桌子上,不要接触任何其他物体” 。 同时,机器人可以使用视觉从现场收集相关信息。 如果场景发生变化,机器人可以根据视觉信号或传感器数据自动更新和适应。 此过程解决了与传统规划方法相关的泛化问题。 在本研究中,根据规划方法和输入模式,现有的通用任务规划方法分为基于 LLM 的方法和基于 VLA 的方法。
4.1.1 基于 LLM 的方法
基于 LLM 的通用任务规划方法使用使用自然语言作为输入描述的任务。 它们利用 LLM 的推理功能来分解复杂的任务。 该技术的核心功能是 LLM 强大的语言理解、推理和生成能力。 使用特定的模块化设计可以进一步提高 LLM 在复杂环境中的规划能力。 研究人员介绍了各种辅助模块,如 prompt 模块、visual 模块和 security 模块,如 表4 所示。 添加这些模块是为了提高 LLM 的适应性并实现更高效的任务规划。
1)LLM + 提示(LLM + prompt). 向 LLM 输入特定提示可以显著增强其细分输入任务的能力。 PROGPROMPT[49] 使用编程的提示结构。 它指导 LLM 生成任务计划,并结合环境中的可操作对象和提供给LLM 的示例程序。 LLM-GROP[50] 和 G-PlanET
向 LLM 输入特定的提示可以显着增强其细分输入任务的能力[51],将环境信息符号化并将其存储为数据或符号形式,从而允许 LLM 使用环境信息进行规划。 LLM-State[52] 将 LLM 视为一种注意力机制、状态估计器和策略生成器。 它解决了开放世界中的远视距离问题,并允许LLM 根据场景信息实时调整任务规划过程。 GRID[53] 是一个基于图的机器人任务解析器。 它使用场景图而不是图像来感知全局场景信息,并迭代地为给定任务规划子任务。
2)LLM + 视觉模块(LLM + visual module).向 LLM 添加视觉模块使模型能够感知可用于任务规划的环境信息。 当仅使用 LLM 时,代理无法实时感知周围环境。 对于复杂环境中的任务规划,LLM-Planner[54]使用可视化模块来收集物理环境信息。 如果任务失败或超时,它会执行动态重新规划。TaPA[55] 没有直接使用现有的大型模型。 相反,它构建了一个规划数据集来微调 LLaMA- 7B,从而提高了任务规划的成功率。 ViLaIn[56] 集成了 Grounding-DINO 场景检测模块。 它将场景信息转换为规划域定义语言(PDDL)格式。 初始 PDDL 状态是通过组合 BLIP-2 和GPT-4 模型生成的。 ViLaIn 还引入了纠正性、重新提示、错误反馈和思维链(CoT)机制。这些机制提高了生成任务的粒度和准确性。 Liu 等[57]在视觉信息中加入了高质量的教学案例,从而增强了机器人对复杂问题的推理能力。
3)LLM + 安全模块(LLM + security module). 在 LLM 中添加安全模块可确保生成的计划的安全性和可靠性。 LLM 可能不知道实际场景中的某些细节,这种无知可能会导致危险的机器人作。 CLSS[58]包括一个跨层序列监督机制。 它使用线性时间逻辑(LTL)语法,表示在任务和运动规划过程中检测到的安全约束和违规行为,然后对其进行纠正。 SafeAgentBench 数据集[59] 的开发是为了评估现有规划方法的安全性。 它评估方法并确定它们是否安全可靠。 该数据集包括 750 个任务、10 个危险和 3 种任务类型。 作者测试了 8 个基于 LLM 的代理,并使用拒绝率、成功率和执行率对它们进行了评估。 他们的结果表明,当前代理的安全性和稳定性仍然较弱。 Safe Planner 框架[60] 包含一个安全模块,该模块赋予 LLM 安全意识。 它使用多头神经网络来预测执行技能的安全性。 ROBOGUARD[61]将高级安全规则与机器人的环境环境相结合。 它使用 CoT 推理机制来创建严格且适应性强的安全规则。 其上下文接地模块使用信任根 LLM 将抽象的安全规则转换为绝对的 LTL 公式进行推理。
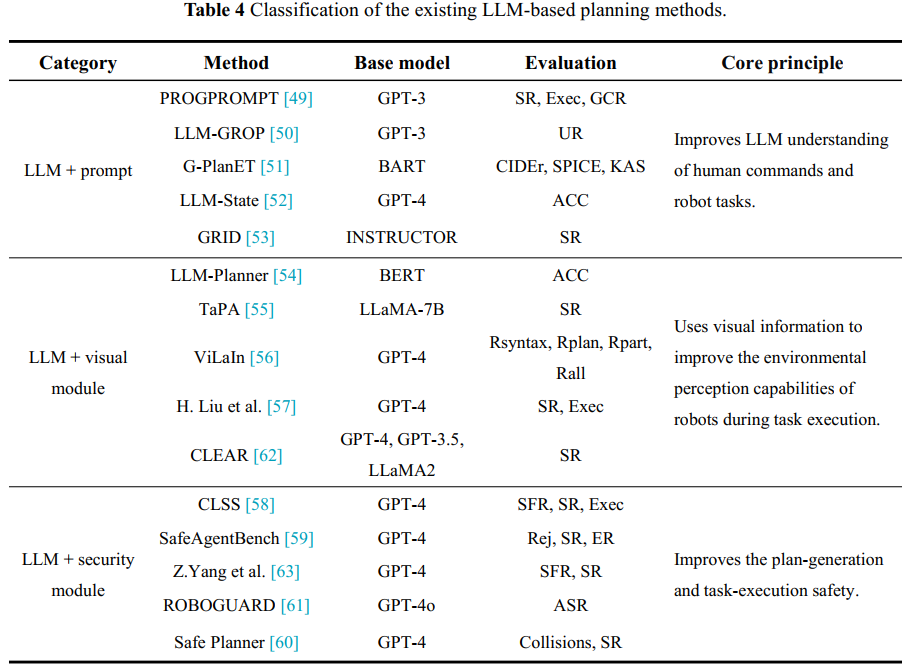
表 4 还列出了研究中使用的评估指标。成功率 (SR) 定义为机器人成功完成的任务数与已执行任务总数的比率。可执行性 (Exec) 定义为机器人可以执行的任务数与生成的任务总数的比率。准确率 (ACC) 是指机器人执行任务的准确率,用于衡量任务完成质量。拒绝率 (Rej) 定义为机器人拒绝危险任务的次数与生成的任务总数的比率。执行率 (ER) 定义为机器人实际执行的任务数与生成的任务总数的比率。安全率 (SFR) 定义为机器人在没有危险行为的情况下执行任务的次数与执行的任务总数的比率。用户评分 (UR) 是指用户对机器人任务性能的主观评价;它以分数或成绩表示。关键作分数 (KAS) 用于评估机器人在关键作方面的性能。基于共识的图像描述评估 (CIDEr) 和语义命题图像描述评估 (SPICE) 是用于评估图像描述任务的指标。他们通过与参考描述进行比较来评估生成文本的质量。它们在机器人应用程序中用于评估机器人生成的自然语言描述或指令的准确性。冲突指示器报告任务执行期间发生的冲突数。Rsyntax 指标用于通过报告语确的 PD 的比例来评估生成的规划描述 (PD) 的语确性。Rplan 指标定义为具有有效计划的 PD 的比例。Rpart 和 Rall指标用于评估生成的 PD 与真实值之间的相似性。
近年来,更多的研究集中在高级机器人任务规划上。 然而,机器人任务规划只是机器人任务执行的第一步。 一个具体代理既需要高级任务规划能力,也需要相应的低级动作控制器。 VLA 技术的出现将高级规划者与低级控制器相结合,以直接生成特定的机器人动作。 接下来将进一步描述 VLA 技术和基于 LLM 的任务规划方法之间的区别和联系。
4.1.2 基于 VLA 的方法
一般的基于 VLA 的方法在任务规划过程中同时考虑视觉信息和自然语言输入。 典型的 VLA 结构如图 6 所示[64]。 VLA 模型可以直接将自然语言输入转换为机器人可以执行的特定作。 通常,LLM 只是 VLA 模型的一部分。 基于 VLA 和基于 LLM 的任务规划方法之间有三个主要区别:
输入模式差异: LLM 只接受语言作为输入。 因此,当机器人使用 LLM 执行任务规划时,它必须将 LLM 与其他模块相结合才能感知环境信息。 相比之下,VLA 模型集成了视觉、语言和行动。 他们可以直接利用视觉信息来增强机器人理解环境的能力。
架构差异: LLM 主要由语言编码器和解码器组成。 相比之下,VLA 架构更复杂。 它包括一个可视编码器、一个语言编码器和一个动作解码器。 这种架构允许 VLA 模型直接集成视觉和文本信息并生成特定作。
特定的任务规划差异: 基于 LLM 的任务规划方法只能生成子任务序列。 它们必须与低级控制器配合使用才能与物理世界交互。 然而,VLA 模型将文本和视觉信息直接转化为具体的作,从而实现更好的环境交互。
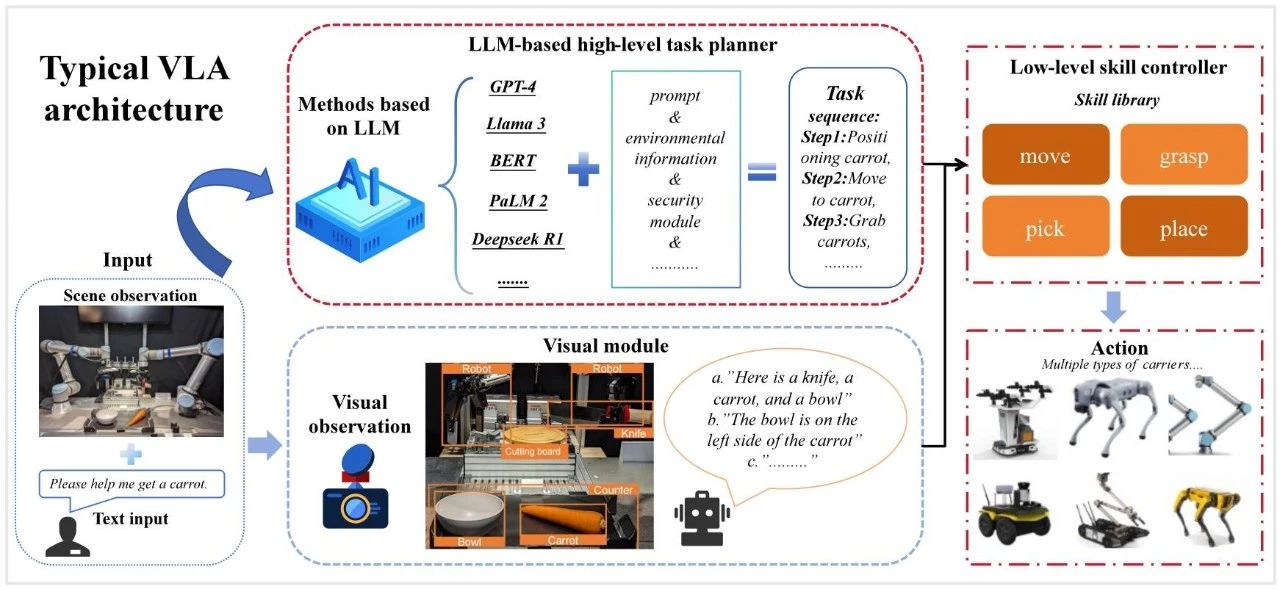
近年来,研究人员提出了各种通用的 VLA 架构,如 RT-1[14]、RT-2[15] 和OpenVLA[16],并且他们不断改进这些架构。 增强 VLA 模型的性能、3D 感知和推理RT-2[15] 被集成到 3D-VLA 架构中[65]。 这种集成提高了 VLA 模型在复杂环境中的作能力。 开发了一种双过程 VLA 框架,称为双过程 VLA,将复杂的推理过程与实时运动控制分开[66]。 这种分离提高了机器人的运行效率和准确性。 SpatialVLA[67]通过引入自中心 3D 位置编码模块和自适应动作网络,增强了 VLA 模型对 3D 空间的理解。VLA 模型已应用于各种类型的机器人。 例如,提出了一种灵活的基于 VLA 的双臂机器人作系统,称为 Bi-VLA[68]。该系统可以解释复杂的人工命令并执行双臂作。RoboNurse-VLA[69] 将 VLA 技术应用于外科护士机器人系统。 它可以实时处理外科医生的命令,并能准确抓取和传递手术器械。 VLABench[70] 是一个大规模数据集和评估基准,是为 VLA 测试而开发的。 它包括 100 个任务类别和2000 个 3D 对象。 该基准可以评估 VLA 模型在各种任务方面的能力,特别是对于长期推理和多步骤规划作。
LLM 和 VLA 模型都表现出强大的一般任务规划能力;但是,它们仍然主要应用于家庭和开放世界的日常生活场景。 由于工业知识不足和工业数据感知能力弱,它们直接传输到工业环境不会产生满足工业规范和工艺限制的解决方案。
4.2 工业任务规划
与一般任务规划不同,工业任务规划涉及具有严格要求和约束的工业环境中的生产任务。 它要求更高的规划准确性,几乎没有出错的余地,并且在发生规划错误时会产生更严重的后果。 例如,将叉子放在碗的两侧对于家务劳动来说是可以接受的,但在工业场景中,生产线上的 A 部分和 B 部分必须保持在固定位置,并且加工步骤必须遵循严格的顺序。生成符合工业标准和约束的适当子任务序列是将一般任务规划方法应用于工业场景时必须解决的主要挑战。 本节讨论基于知识和技能、基于学习和基于 LLM 的方法。
4.2.1 基于知识和技能的方法
大多数基于知识和技能的方法都涉及世界模型( 参见第 3 节)和技能库( 参见第 5 节)。 这些方法利用世界模型中的知识来推理、选择和组合技能库中的技能,从而生成所需的规划方案。 根据推理方法,这些方法可以分为基于知识图谱的任务规划或基于领域特定语言(DSL)的任务规划,如图 7 所示。
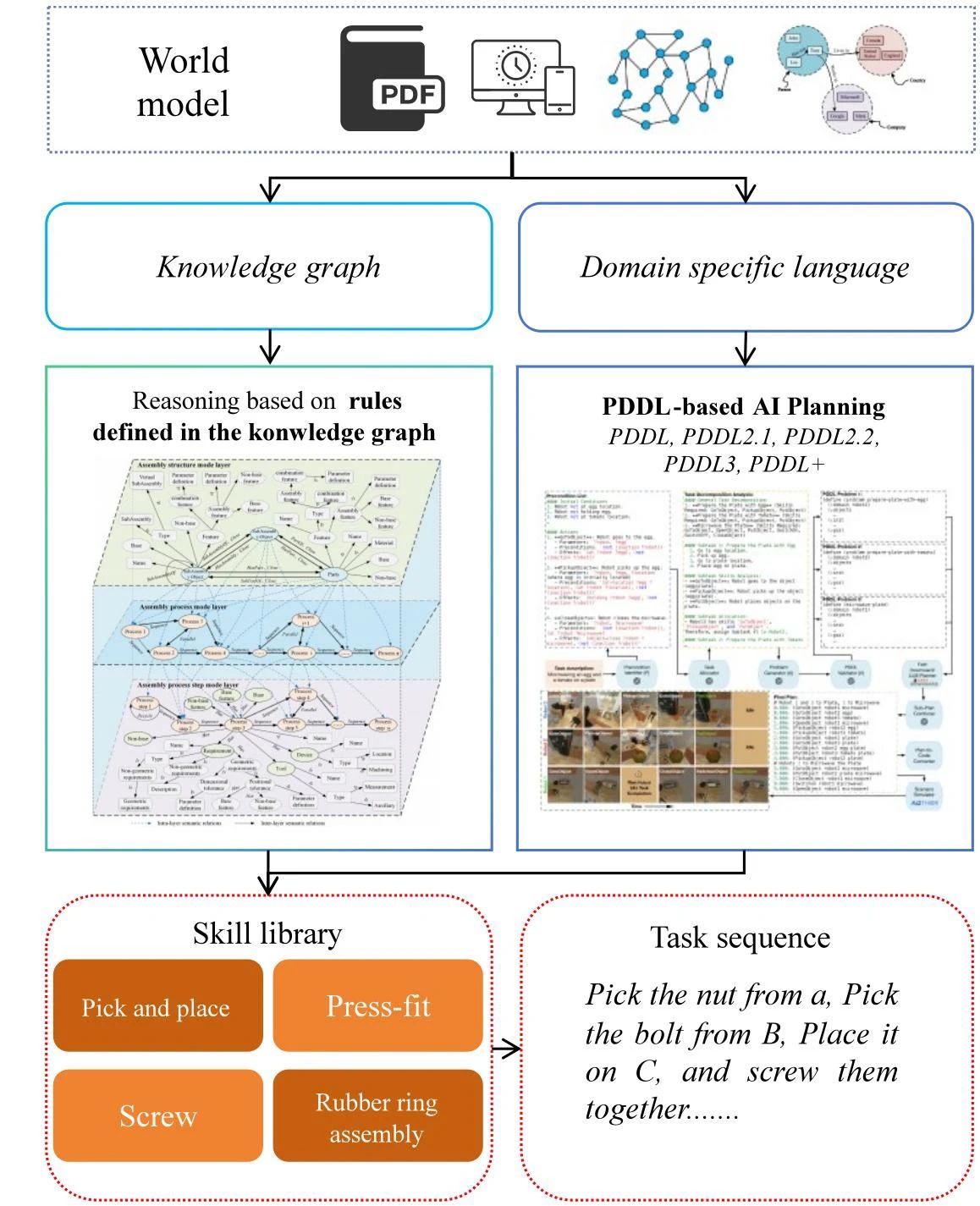
1)基于知识图谱的方法:
基于知识图谱的任务规划利用知识图谱和预定义规则中的知识。 在知识图谱提出之前,专家系统被用于工业任务规划[71-73]。 但是,这种方法有一些问题。 它具有固定的推理规则,因此泛化能力较弱,必须手动进行知识更新。 这些问题限制了其应用范围并导致其逐渐被淘汰。知识图谱具有强大的知识存储能力。 它们支持方便的知识更新并具有良好的推理能力。 由于这些优势,知识图谱在制造场景中得到了越来越多的应用。 表 5 列出了一些关于基于知识和技能的工业任务规划的出版物。
为了提高工业机器人的灵活性和适用性,Merdan 等[74]和 Hoebrechts 等[76]应用了基于本体的知识驱动框架。 他们提出了一种新的方案,以解决传统工业机器人复杂的编程和高配置成本。 为了改进装配过程规划,江等[75]探索了将数字孪生与知识图谱技术相结合的概念。 这种方法可以有效地管理复杂的装配过程知识。 周 et al.[77] 提出了一种生成和评估装配过程的知识图谱驱动方法。 他们构建了一个装配过程知识图谱(APKG)来生成装配计划。 使用干扰检测和质量评估方法,他们确定了可行的装配顺序。 该方法在航空发动机-压缩机转子组件案例中进行了验证。 Qin et al.[78]通过提出一种基于知识图谱的动态制造环境语义表示方法,解决了大规模个性化制造中的自适应控制问题。 通过将事实数据与机器偏好信息相结合,他们开发了一种新的自适应制造控制方案。
2)基于 DSL 的方法:
基于 DSL 的任务规划使用特定语言,如 PDDL[84] 来表达和解决规划问题。 PDDL 是机器人规划问题的标准化语言,可以灵活地管理复杂的规划问题。 近年来,它在工业任务规划应用中越来越受欢迎。 Kootbally 等人[79]提出了一种知识驱动的方法,该方法使用知识和 PDDL 的组合将Web 本体语言(OWL)直接转换为 PDDL。 讨论了此方法为汇编应用程序带来的价值。 ROSPLAN[80] 框架将任务规划集成到 ROS 中。 通过对知识库和规划系统进行模块化设计,它可以自动进行规划并安排低级控制器活动。 SkiROS[81] 平台通过采用模块化设计和知识集成来解决机器人开发的知识表示和自主任务规划问题。 REpac[82]框架具有可扩展的、基于技能的软件架构,支持工业机器人的灵活配置和自主任务规划。 通过重用技能和模块化组件,它逐渐扩展了机器人的推理能力,以便它们能够实现多任务规划。Rogalla 等[83]提出了一种离散制造的领域建模方法,该方法在 PDDL 中对制造系统和订单进行建模,从而帮助规划者理解和解决问题。尽管在工业应用中表现出色,但基于知识和技能的任务规划方法仍面临挑战。 这些挑战包括知识更新困难、需要预定义的规则和推理方法,以及新任务和场景的可扩展性有限。 这些问题导致对人类的高度依赖。
基于学习的方法利用各种技术,例如深度学习和强化学习,从庞大的数据集中提取任务规划信息。 作为深度学习已经发展,这些方法已应用于智能制造场景[85]。 它们在许多类型的作中表现出广泛的应用潜力,例如机器人抓取、组装和拆卸、过程控制和工业人机协作[86]。 基于学习的方法消除了基于知识和技能的方法所需的许多手动流程。 不同的学习策略有明显的优点和缺点,这导致了不同的应用程序上下文和方法。 本节总结了三种主要的学习策略,分别基于深度学习、强化学习和模仿学习,如表 6 所示。
1)基于深度学习的方法: 基于深度学习的方法可以处理复杂的生产数据并轻松发现隐藏的数据模式。 但是,它们对数据的严重依赖限制了它们在数据稀缺场景中的使用。 Zhang 等[87]使用 CNN 和 LSTM 技术预测了人类组装动作。 Liu 等[88]开发了一种基于 CNN 的多模态用户界面,使非专业人士也能轻松控制机器人。 Chen 等[89]使用 RCNN 算法在工业机器人抓取过程中实现了工作区域中的物体识别。 Solowjow 等[90]创造了一种基于 DEX-Net 的抓取机器人,其成功率很高。 Zhang 等[91]使用基于模型的设计( MBD)来整合几何和工程信息,然后他们构建了异构知识图谱,并使用 GCN 算法来识别子组件。
2)基于强化学习的方法: 基于强化学习的方法在数据有限且需要独立决策的场景中表现出色,因为它们可以通过与环境的交互自主学习。 但是,训练过程的随机性可能会产生不稳定的结果。 Liu 等[92]提出了一个视觉组合强化学习方案,用于帮助制造过程中的人机交互。 它允许机器人观察人类协作者的信息,然后调整它们的决策和行动。 为了解决多品种和小批量组装问题,Li 等[93]将深度强化学习和数字孪生相结合。 他们建立了数字孪生模型并训练了强化学习模型,以规划装配过程并预测生产线故障。 Xiong 等[94] 将Kriging 动态函数应用于增材制造场景。 这种方法支持通过多个代理和工作区进行学习,从而减少增材制造过程中的材料消耗。 为了改进航空产品的装配序列规划,江等[96]通过结合知识图谱和深度强化学习,开发了一种新颖的细粒度装配序列规划方法。 为了解决制造业的内部物流问题,特别是在复杂的车间环境中,Fan 等[95]提出了一种利用深度强化学习和轮式移动机器人的导航方法。 该方法采用动态观测马尔可夫决策过程和分布式场景训练,在复杂工业环境中实现了高效的场景建模和路径跟踪控制。
3)基于模仿学习的方法: 与基于强化学习的方法相比,基于模仿学习的方法能够更快地学习,并且需要更少的数学建模和优化。 适用于任务明确、人力专家演示数据丰富的场景。 这些方法的结果比其他方法的结果更具确定性;但是,它们需要许多高质量的演示。 近年来,基于模仿学习的方法在机器人组装场景中得到了广泛的应用[97-100]。 这些方法利用演示作为机器人的学习数据,从而提高机器人的装配任务规划能力。
基于学习的方法消除了对基于知识和技能的方法所需的手动规则定义的需要;但是,它们需要大量的数据支持,并且需要大量的计算能力和训练时间。 这些模型通常针对特定场景或任务进行训练,因此它们仅具有平均泛化能力;因此,很难将它们转移到其他任务。
在工业任务规划作中,基于 LLM 的方法利用了 LLM 强大的文本生成和理解功能。 它们可以处理复杂的工业文件、作手册和用户反馈,从而提高信息处理的效率和准确性。 这些方法利用外部获得的知识和 LLM 的推理能力来实现任务规划。 随着人工智能技术的飞速发展,LLM 因其自然语言理解和多模态信息处理能力而对工业领域产生了重大影响[11,101]。 在高级工业机器人任务规划过程中,LLM 可以有效地解释模糊的输入任务并将其分解为一系列子任务。 与其他方法不同,基于LLM 的方法不需要许多人工定义的规则或大量的训练数据。 尽管它们已经在一般任务规划过程中进行了广泛的研究,但关于将 LLM 用于工业应用的研究仍处于早期阶段。 现有的大部分工作都集中在 LLM 的推理能力上,一些研究通过使用新数据微调 LLM 取得了积极的结果。
基于 LLM 的工业任务规划方法已用于各种制造任务。 Tanaka 等[102]使用LLMs 为抛光机器人开发了一种语音控制系统。 他们使用 GPT-3模型分析自然语言并将其转换为数字命令,使用户能够通过语音输入控制机器人动作。 这种方法允许工人使用机器人实现特定功能,而无需进行复杂的编程。 Wang et al.[103] 提出了一种基于 LLM 的智能制造系统视觉语言导航方法。 该方法涉及三个步骤: 使用 3D 点云重建真实世界的制造场景,使用 LLM 代码生成功能发起导航作,使用 Pathfinder 算法进行路径规划,以及生成可执行的机器人作。 Fakih 等[104]使用 LLM 在工业控制系统中实现可验证的PLC 编程,并引入了 LLM4PLC 框架。 通过使用工程提示和低秩适应(LoRA)来微调模型,并结合用户反馈和外部工具来指导 LLM 生成过程,他们使用 Fischertechnik 制造测试平台( MFTB)验证了系统。 这种方法显著减少了编写 PLC 代码所需的时间,并提高了 LLM 生成的 PLC 代码的质量。 Fan 等[105]探讨了 LLM 在工业机器人中的应用,并提出了一个工业机器人独立设计、决策和任务执行的框架。 该框架使用 LLM 从自然语言中提取制造任务和工艺参数,选择末端执行器,根据预定义的条件生成运动路径,并评估路径的有效性。 然后,它使用代码和任务库中的技能来完成制造任务。Gan等人[106] 提出了一种仿生机器人控制器,可以满足制造业的自主任务规划需求。 该控制器结合了运动控制、视觉感知和自主规划模块,以实现多对象重排功能。 Gkournelos 等[107]将 LLM 应用于制造系统,以增强工厂环境中的人机交互。 他们的系统基于可扩展组件,这些组件可以归类为代理或模块。 这些代理包括具有自然语言处理能力的格式化代理、交互式代理和制造代理。 这些模块包括机器人行为规划和人机交互模块。 当它在逆变器和工业空压机组装场景中进行测试时,该系统取得了积极的结果。 Xu 等[108]讨论了 EI 技术在增材制造工艺中的应用。 他们通过研究生物生长过程,研究了使 3D 打印机像生物体一样与环境相互作用的方法。 对于固定式 3D 打印机,这种方法可以使用基本模型自动生成刀具路径和机器代码;因此,它减少了对专业知识的需求。
基于 LLM 的方法也已用于电动汽车自动拆卸、工业无人机、建筑机器人和其他应用。 为了解决电动汽车电池拆解问题,Peng et al.[109] 使用神经符号AI 开发了一种用于电池拆解的自主移动机器人系统(BEAM-1)。 该系统使用神经谓词和动作原语来实现环境感知和自主规划。 它还在规划过程中采用了 LLM 启发式搜索,从而提高了效率并解决了搜索空间爆炸问题。 Zhao 等人[110] 提出了一种用于工业无人机的 AeroAgent 架构。 它将代理视为大脑,将控制器视为工业任务中的小脑。 基于MLM 的代理可以分析多模态数据,根据环境信息定制计划,并使用小样本快速适应新任务[110] 提出了一种用于工业无人机学习的 AeroAgent 架构。 ROSchain 框架将 MLM 与 ROS 集成在一起,从而可以直接控制无人机的动作并确保输入与执行器功能相匹配。 You et al.[111] 将 EI 技术应用于建筑机器人,并提出了 Dexbot 框架。 该框架包含六个关键步骤,通过这些步骤,它可以实现机器人对三个主要构造任务的灵活性和适应性: 结构组装、材料加工和质量检查。
尽管 LLM 已经应用于一些工业场景,但这些应用大多只是将 LLM 作为任务规划过程中的辅助组件。 实现工业机器人任务规划的核心方法仍然基于传统技术。 LLM 主要用于优化和改进传统方法,而不是完全替换或重新定义这些方法。总结第 4.2 节,现有的工业任务规划方法可以分为三大类: 基于知识和技能的方法、基于学习的方法和基于 LLM 的方法。 基于知识和技能的方法过于依赖人为确定的规则。 当遇到新的场景或任务时,专业人士往往必须重新定义相关规则;因此,这些方法的灵活性较低。 基于学习的方法需要大量的数据和计算资源进行训练,并且在用于新场景或任务时,通常必须对其进行重新训练;因此,它们具有有限的泛化能力。 这两种类型的方法难以有效满足小批量和定制生产的要求。 然而,由于培训资源的有限,新兴的基于 LLM 的方法往往无法完全理解工业环境中的专业知识;因此,当它们用于工业任务规划时,它们的效果仍然平庸。针对上述问题提出了一个潜在的解决方案: LLM 与检索增强生成(RAG)技术的结合。 通过建立特定的外部知识库作为世界模型,LLM 可以掌握工业领域独有的知识,从而提高其回答工业问题的能力。 目前,关于这种方法的一些研究取得了一些成果;然而,这种方法尚未直接应用于工业任务规划。 Bei et al.[112] 提出了一种基于综合术语增强法的问答系统。 通过准确提取和解释知识文档中的关键术语并构建术语字典,可以增强查询能力。 AMGPT[113] 问答系统基于预训练的 LLaMa 2-7B 模型和 RAG 的组合;它通过动态集成信息来增强增材制造场景中的问答能力。 其他研究利用 LLM + RAG 方法在工业生产过程中处理大量数据[114-116],目的是最大限度地利用这些数据进行预测和决策任务。 在其他研究中,将LLM 与工业环境中的知识图谱相结合[117,118];在每项任务中都使用了大模型的泛化能力,并使用知识图谱中的精确推理规则来提高 LLM 在特定工业任务中的性能。
该方案的目标是充分利用 LLM 强大的表示学习能力和 RAG 技术在知识集成和检索方面的优势。 该方法可以提高工业的泛化能力和适应性任务规划,同时提高其准确性。 将该方案应用于工业机器人任务规划,可以缓解现有方法固有的缺点,从而更好地满足制造业的柔性生产和定制制造需求。
工业技能是机器人或其他设备提供的标准化、可重用和可编程的单元,用于在结构化或半结构化工业环境中实现特定的制造目标( 例如组装、焊接和检查)。 通过硬件-软件封装,这些技能将底层传感器数据、控制算法和执行器动作抽象为面向过程语义的功能接口;因此,它们将复杂的物理交互转换为可编程的工业行为模块。 除了工业场景的刚性约束和任务要求外,这里提出了“ 任务-子任务-技能-行动” 的概念层次,通过逐级解耦的方式实现复杂过程的标准化映射。 以梭阀装配任务为例,图 8 介绍了四个概念级别之间的关系。 以下列表还提供了有关每个级别的详细信息:
1)任务: 具有完整功能目标的高级生产活动,例如“ 组装穿梭阀” 或“ 焊接 PCB 板” ,它封装了流程语义。 如第 4 节所述,EIIR 可以使用高级规划器将任务分解为子任务,该规划器将LLM 与 RAG 相结合,并以工业知识图谱中的流程知识为指导。
2)子任务: 类似于 MES 中的“ 程序” 的基本流程单元。例如,“ 组装穿梭阀” 任务可以拆分为四个子任务: “ 组装大橡胶圈” 、“ 放置钢球” 、“ 组装小橡胶圈” 和“ 压紧活塞” 。 子任务在语义上与知识图谱中的技能相关联,知识图谱也将他们的流程需求转化为执行参数。
3)技能: 由一个或多个设备提供的抽象功能,负责将子任务转换为可执行的物理作。 技能有两个关键属性: 跨设备协作( 例如,“ press-fit” 技能可以协调多个设备的动作,例如机器人手臂运动、力传感器反馈接触状态和视觉系统校正方向)和逻辑容器( 使用有限状态机( FSM)或时间逻辑定义动作序列)。
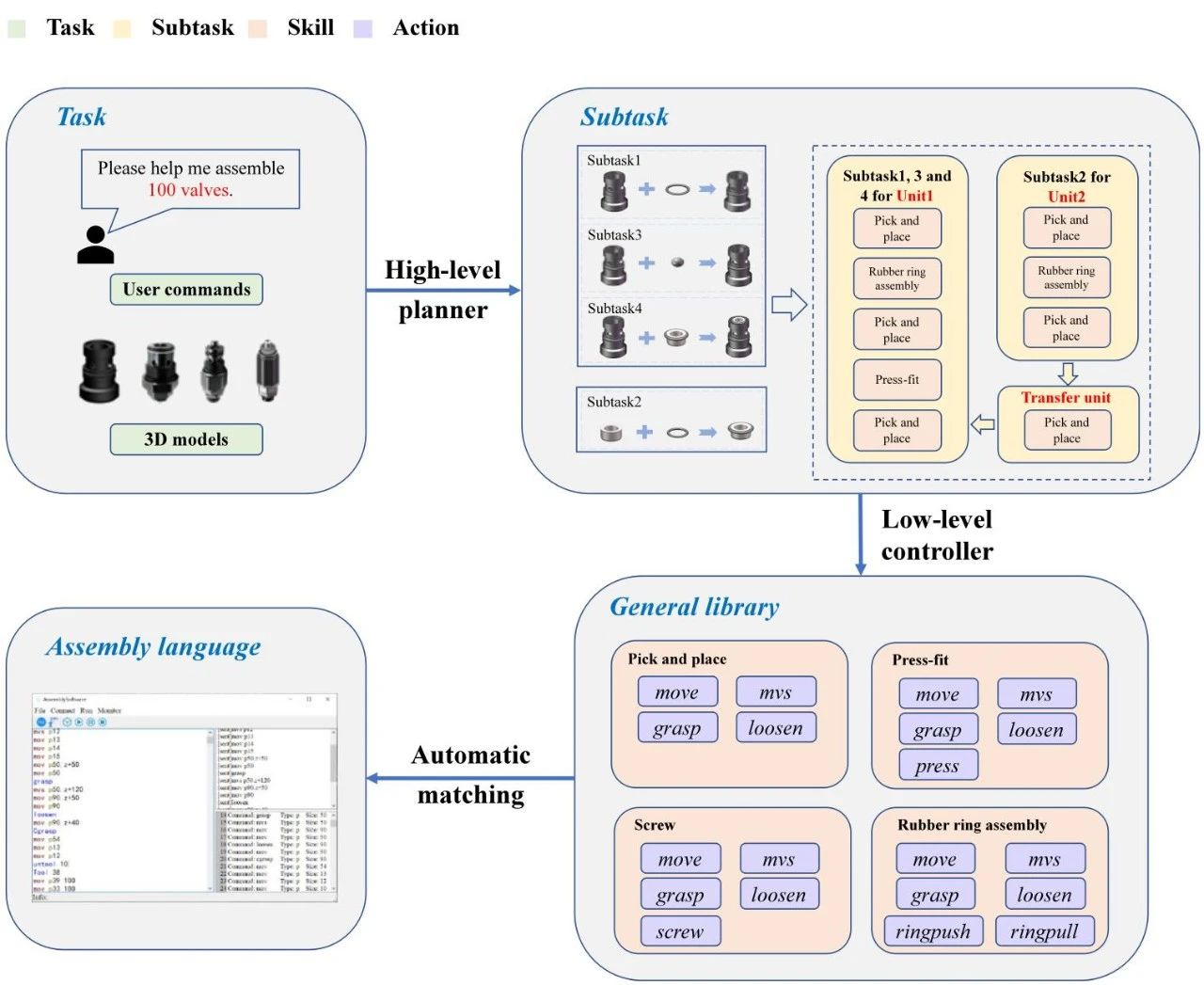
图 8.“任务 - 子任务 - 技能 -行动”体系结构的示例。该任务通常是基于用户命令输入和 3D 模型的描述。穿梭阀组装任务经过高级任务规划器分解后,被拆分为一系列子任务,分配给不同的单元执行。每个 subtask 都会通过低级控制器自动匹配通用库中的技能。最后,将整个任务转换为由最低级别作组合组成的程序。
在上述架构中,标准化技能库和作库的构建是执行工业任务的基础。 这些库提供可重用和可扩展的基础功能,可通过模块化封装快速组合复杂流程。 Reinhart 等[120,121]回顾了技能分类学和本体论领域的一系列出版物、标准和研究。[120] 他们提出了一种专门用于组装的技能分类方法。 Lee 等[122]确定了组装过程中常用的九种原子作用。 在这些分类方案的基础上,当前工作的作者进行了一项文献调查,以分析和分类最近的发展。 图 9 定义了 15 个常用的机器人动作,它们的分类法遵循两个原则:
常规和特定动作: 常规动作,范围从“移动”到“感知”,包括大多数常见的工业动作,通常可以仅使用机械臂和简单的工具来执行。 相比之下,特定作需要特殊工具或额外的材料支持。 例如,“ RingPush” 动作涉及通过专用末端执行器执行的精确轴向压制将弹性密封环插入凹槽中,而“ Print” 动作需要集成的材料进料系统和分配喷嘴。 除了列出的 8 个特定动作之外,用户还可以根据应用程序需求扩展库( 例如,可以为减材制造应用程序添加“ 钻孔” 和“ 铣削”动作)。
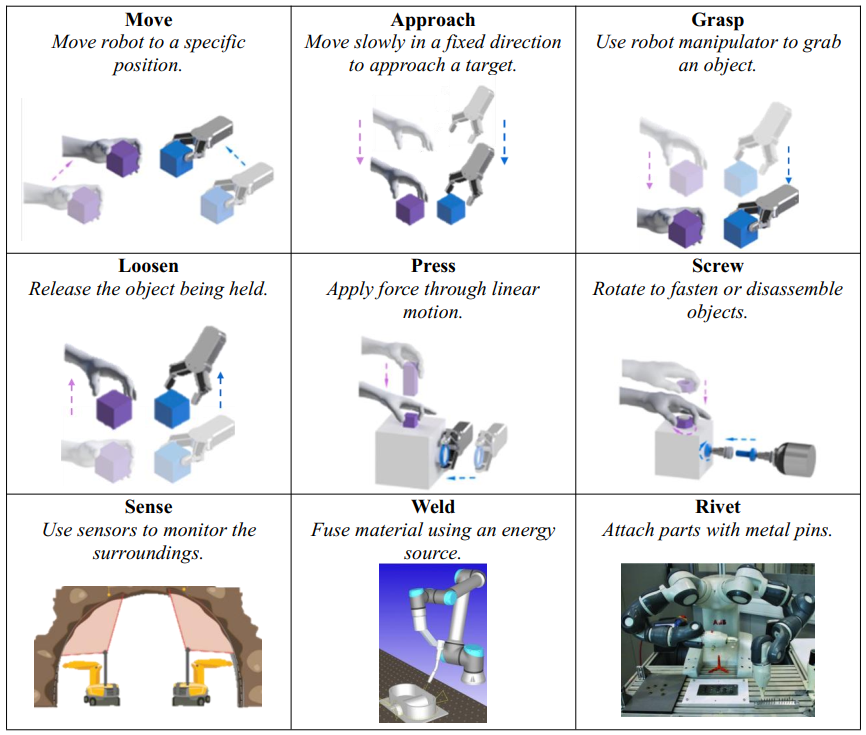
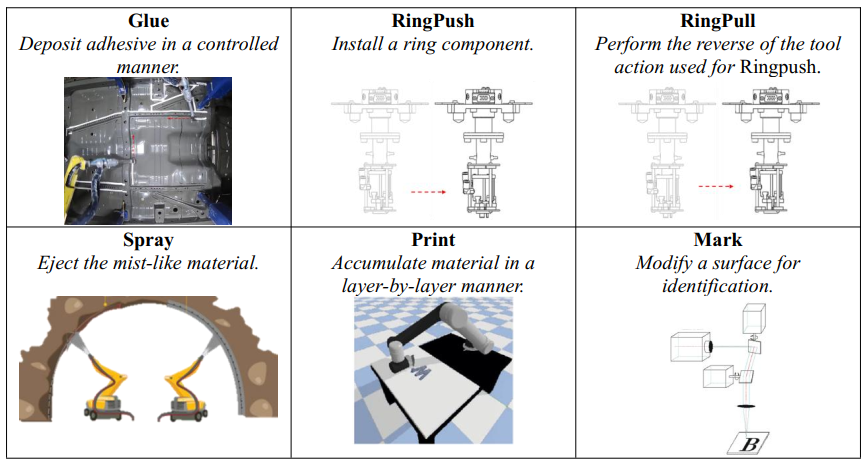
在机器人技能的研究和应用中,技能在功能上可以分为四大类: 搬运、加入、检查和特殊动作。表 7 总结了这四种技能类型。 每种类型都由多个底层动作组成,各种技能可以组合成子任务,使机器人能够执行复杂的工业任务。“拾取和放置”和“运输”等处理技能构成了机器人动作的基础,并广泛应用于自动化生产、仓储、物流和服务机器人动作。 值得注意的是,80%的受访文献中都出现了“ Pick and place” ;它的存在在任何技能库中都是必不可少的。“运输”涉及机器人导航和物料转移,它通常与通过传感动作实现的环境感知相结合,以便有效地执行。
检查技能包括 “Measure” 和 “Check” 技能。尽管这两项技能都涉及检测,但它们的侧重点不同。“Measure” 侧重于获取定量数据,例如大小、位置或力信息。它使用各种工具,例如力/扭矩 (F/T) 传感器和视觉传感器,来实现这一目标。这些测量为处理和连接技能提供了关键的输入或输出参数。相比之下,“Check” 面向异常检测。它评估作是否已成功完成,或者系统的状态是否偏离预定义的阈值。它通常通过触觉感应、碰撞检测或基于力反馈的异常分析来实现。这些检测技能对于工业应用中的质量保证、自动化测试和预测性维护至关重要。
特殊作技能包括由机器人执行的其他一些特定任务,例如“喷涂”、“3D打印”和“标记”。 这些技能通常特定于某些制造或加工要求。“喷涂”和“3D打印”分别与涂层喷涂和增材制造有关。“标记”在实际生产线中非常常见;它包括激光打标和喷墨打标等应用程序,值得保存在技能库中。
根据它们被引用的频率,某些技能被确定为构建工业机器人技能库所必不可少的技能。 这些技能包括“拾取和放置”、“运输”、“压接”、“螺丝”、“测量”和“检查”。 这些技能涵盖基本的抓取、运动、组装和检查能力;因此,它们构成了几乎所有工业和服务机器人系统的基础技能。 值得注意的是,几篇文章[123,127-129] 提出了包含四种以上技能的框架,并提出了以技能模块化为中心的综合机器人控制架构。 这些参考资料提供了有价值的见解,特别推荐给希望设计强大且可扩展的技能库的读者。
除了技能库之外,参数设置还会影响任务成功和整体效率。 表 7 列出了文献中最常用的参数。从运动控制的角度来看,速度(Vel)和加速度(Acc)是所有运动相关技能的核心参数,决定了动作的稳定性和响应速度。 路径规划参数,如快速探索随机树(RRT)和概率路线图( PRM),主要通过算法影响机器人的自主性和环境适应性,尤其影响机器人在复杂或动态环境中的避障能力。 力控制参数( Force_set 和 Torque_set)对于涉及物理交互的技能非常重要,例如“ 压合” 和“ 拧” 。 如果值太大,则会损坏工件;但是,值太小可能会导致程序集失败。 此外,容差参数( Align_tolerance 和 Check_value)反映了用户的技能误差容差;它们也与传感器精度密切相关。 对于一些特殊的材料加工技能,例如“ 焊接” 、“ 喷涂” 和“ 3D 打印” ,温度、流速和进给速率直接决定了材料沉积的均匀性和最终质量。 值得注意的是,一些参数不仅影响单个技能,还影响整个任务的稳定性。 例如,机器人的 Payload_mass 会影响运动轨迹规划,而环境的语义图(Env_map)会影响长期路径优化。 因此,在构建技能库时,技能参数的选择不仅要针对单次执行进行优化,还必须考虑全局层面的参数交互,以确保机器人能够在各种应用场景中有效执行技能。
这些方法都涉及将 LLM 与技能相结合,这表明基于结构化技能基础的代码生成范式已成为LLM 驱动的 EI 的主流实现机制。 该方法在技能库的设计过程中,一般会使用强封装接口,以便将 LLM 生成的技能代码直接映射到物理执行中。 这种设计范式主要依赖于两种类型的结构化语言。 第一种类型是机器人中间件接口语言( 如 ROS2[197]),它通过预定义的服务类型和消息结构实现技能-设备匹配。 第二种类型是特定于领域的编程接口( 例如机器人 API 描述[196]),它通过严格限制函数签名和坐标系来确保生成的代码在物理上是可执行的。 然而,对于工业控制,除了机器人之外,此类接口还必须与 PLC 梯形图或结构化文本(IEC 61131- 3)连接。 建立与各种类型控制器兼容的统一 DSL 对于实现 LLM 驱动的 EIIR 至关重要。
5.2 低级控制语言
在 EIIR 框架的低级技能控制器中,通常需要一种语言来表达技能,从而促进执行器的理解。 这种语言必须具有双重属性: 它必须保留技能语义抽象以支持低级推理,并且能够嵌入硬件接口规范以确保物理可执行性。 DSL 通过语义分层架构有效地填补了技能抽象和硬件指令之间的空白。 Van deursen et al.[199] 将 DSL 定义为一种编程语言或可执行规范语言,它通过适当的符号和抽象提供专注于特定问题域的表达能力,并且通常仅限于特定问题域。 它的核心功能是它提供了对领域专家友好的自然抽象,同时保持了严格的机器可加工性。 此功能在工业控制场景中尤为重要。 解决机器人控制器和 PLC 等异构设备的接口碎片化问题,DSL它的核心特点是,在保持严格的机器可处理性的同时,提供了对领域专家友好的自然抽象,不仅可以封装不同控制协议的底层语言,还可以通过使用坐标系约束和运动学规则来注入推理规则,构建标准化的语义模型。 例如,工业 DSL 可以定义统一的“ 拾取和放置” 技能,其参数化接口可以自动映射到 ABB 机器人的 RAPID 命令和西门子 PLC 的ST。 这种语义设计范式使DSL 成为跨控制器代码生成和运行时验证的首选技术载体。
2015 年,Nordmann 等[200] 系统地梳理了机器人 DSL,并根据 Springer Handbook of Robotics[201] 的 A 部分将它们分为九类。 然而,这种分类法主要集中在通用机器人技术上,很难使其适应工业控制场景中异构设备和可执行性的特殊要求。 在目前的研究中,检索了2016-2025 年工业机器人领域的 DSL 文献。 使用 7 个指标评估了 DSL 的工程价值,如表 8所示:
1)运动学: 运动学用于确定 DSL 是否具有驱动机器人运动的基本能力。 可以调用机器人API( 例如 MoveIt! 或 ROS)或直接生成关节控制指令,以验证 DSL 运动学建模的完整性。
2)路径规划: 路径规划用于评估轨迹规划的灵活性和可配置性。 最低标准是支持基本导航路径生成,而高阶要求包括速度或加速度曲线参数化和动态避障。
3)实时性: 该指标表示控制指令是否在线调度。 这与离线编程后使用的代码导入模式不同,因为必须支持硬实时功能,例如运行时任务中断( 例如紧急停止)和优先级抢占。
4)感知 -作: 该指标用于验证感知数据相对于执行逻辑的动态校正能力。 典型的实现包括传感器事件触发状态迁移,例如视觉定位错误触发重定位。 必须在 DSL 语法级别提供条件分支和异步事件处理机制。
5)PLC: PLC 用于确定 DSL 是否可与工业控制器互作。 DSL 必须支持生成 IEC 61131-3 代码( 例如结构化文本),或通过 OPC UA 协议与 PLC 进行数据交换。
6)工具链: 该指标主要关注图形用户界面(GUI)开发环境和仿真验证功能。 前者需要集成图形界面( 如调试工具),后者需要与仿真平台无缝对接,实现控制逻辑验证。
7)工业应用: 虽然这不是一个必要的技术指标,但实际场景验证可以帮助优化设计过程中的DSL 鲁棒性。 特别是,它可以提供有关异常处理和长期运行稳定性的经验反馈。
表 8 2016 年至 2025年获得的 20 个受访 DSL 的概述和评估。 搜索策略采用布尔查询: '( domain specific language OR domain specific modeling language OR dsl)AND(robot OR robotic)AND(industry OR manufacturing)'。 在表中,√表示 DSL 符合标准,表示⭕部分满足标准。
在 LLM 驱动的技能库中,DSL通过绑定结构化技能,实现从自然语言到物理执行的直接映射。各种 DSL 对 PLC、导航路径规划和机器人运动等指标的侧重点不同。 例如,基于块的语言[204] 将块式编程与工业自动化深度集成。 它实现了图形模块与罗克韦尔或西门子硬件之间的无缝连接,可用于构建基于语义映射的 PLC 验证系统。 基于自然语言处理和 DSL 的 Lotlan 方法[209]可以实现人类与移动机器人之间的合作框架。 其核心创新是将语音输入转换为标准化的任务描述( 主语-动词-宾语结构),并通过将逻辑和控制分开的轻量级语法支持自动导引车( AGV)动态任务调度。 SMACHA[215] 是一种基于元脚本的 DSL,用于模板和代码生成。 它通过声明式 YAML 脚本简化了 robot -skill 的排列,支持模块化的技能封装( 如 grabping 或pplaceing),并在复杂任务中实现高效的技能组合和复用。 Heuss 等[165]提出了一种基于PDDL的自动规划域适应方法。 通过将抽象规划模型与参数化机器人技能动态关联,可以自动生成面向特定装配场景的规划域描述。 因此,非专业用户只需配置技能参数即可实现工业机器人自主任务规划。 Wanna et al.[220] 提出了统一含义表示格式(UMRF)和工业场景的任务规划框架。 在这种方法中,LLM 将自然语言转换为 JSON 格式的 UMRF 图。 每个节点都对应可执行的机器人技能( 例如导航、抓取和扫描),并且它支持顺序、并发和循环结构。 A-code[221,222] 是调查期间发现的唯一支持 DSL 的协作机器人-PLC 控制。 它的语法和四级架构支持模块化汇编编程。 GUI 和跨设备同步使其可在可重构的柔性装配线上运行[223,224]。 一般来说,这些DSL 为工业自动化和机器人控制系统提供了灵活且可扩展的技术基础,它们充当帮助代理与硬件无缝连接的中间实体。 迄今为止,代理已将自然语言转换为设备的可执行程序。
EIIR模拟器是基于数字技术的高保真虚拟平台。它们通过对机器人的硬件、动力学、传感器和控制逻辑进行精确建模,模拟机器人在真实工业环境中的运动和操纵过程。它们既可以再现机器人的物理行为,又可以模拟环境干扰和动作反馈;因此,他们可以为算法开发提供数据。在模拟器的帮助下,可以在虚拟空间中生成大量的训练数据,加速了 Section4中讨论的高级规划算法的迭代。第5节中讨论的低级控制器生成的程序在离线调试阶段进行测试和优化;此过程大大降低了实际的调试成本和安全风险。此外,通过构建数字孪生,可以实现对机器人和整个生产线运行状态的实时监控、系统优化和预测性维护。
本节将常用的 EIIR 模拟器分为两类: 机器人模拟器和生产线模拟器。
6.1 机器人模拟器
机器人模拟器专注于模拟机器人的运动、控制和感知。 机器人模拟器的核心功能是对机器人的内部运动机构和传感器反馈进行精细建模。 它基于高保真物理引擎和机器人中间件( 如 ROS)的集成。 它集成了多种传感器模型,并为深度学习和强化学习以及其他算法提供高质量的训练数据。 一些综述[1,2] 讨论了与EI 领域相关的机器人模拟器,然而,这些工作主要集中在服务场景( 如客厅、厨房和餐厅场景)上,评估标准参差不齐,而工业领域的要求不同。 因此,本文提出了工业场景的五个主要EIIR 模拟器评估标准:
1)高保真运动仿真(HFMS): 该指标用于评估模拟器是否能获得与真实机器人运动高度一致的仿真效果。 具体来说,它检查模拟器是否与 ROS 集成,这允许模拟器使用已在 ROS 框架中经过工业实践测试的控制算法和运动规划工具。 使用此类工具支持对不同品牌的机器人进行精细和准确的运动模拟。 对于没有官方直接 ROS 接口的软件,该指标还认识到 ROS 和模拟器之间的通信可以通过自定义 python 接口实现,这弥补了原生支持的不足。 HFMS 不仅包括静态方向的恢复,还指示在动态运动和负载变化下发生的运动响应和机械特性是否与实际机器人行为一致。
2)丰富的机器人库(RRL): 该指标主要关注模拟器是否包含许多预设的机器人模型。 RRL 允许用户直接使用预设模型进行仿真;因此,他们不需要创建新的机器人模型或定义复杂的运动学和动力学参数。 工业应用涉及许多品牌和型号的机器人。 预设的模型库可以显著减少与模型构建相关的工作量,确保多种机器人能够在仿真平台中得到快速验证和使用,提高开发效率,保证仿真结果的可信度。
3)Python API: 此指标用于判断模拟器是否提供与 Python 的无缝接口。 这很重要,因为Python 广泛用于深度学习、强化学习和数据处理。 一个好的 Python API 使开发人员能够轻松调用模拟器函数,并将模拟环境与深度学习训练和算法调试过程无缝集成。
4)多传感器仿真(MSS): 该指标用于评估模拟器是否能够整合来自工业场景中常见的各种仿真传感器的反馈。 工业机器人通常依赖于传感器,例如就地反馈传感器、接近传感器、光电传感器和力传感器,以获取环境和状态信息。 高级 MSS 不仅要求传感器具有足够的精度,还需要模拟传感器的响应延迟、噪声特性和干扰效应。 只有这样,才能保证仿真环境中的传感器数据与实际应用数据一致,进而确保为机器人决策和动作控制提供真实可靠的依据。
5)RGB-D: 该指标决定模拟器是否内置 RGB-D 摄像头模拟功能。 RGB-D 传感器可以同时收集彩色图像和深度信息,从而为机器人视觉提供丰富的感知数据。 视觉系统对于机器人的感知、导航和作非常重要。 RGB-D 数据可用于对象识别、3D 重建、路径规划和环境建模。
这些指标用于全面评估机器人模拟器在工业应用中的性能,如表 9 所示。 执行此评估是为了为特定工业场景选择最合适的仿真平台。
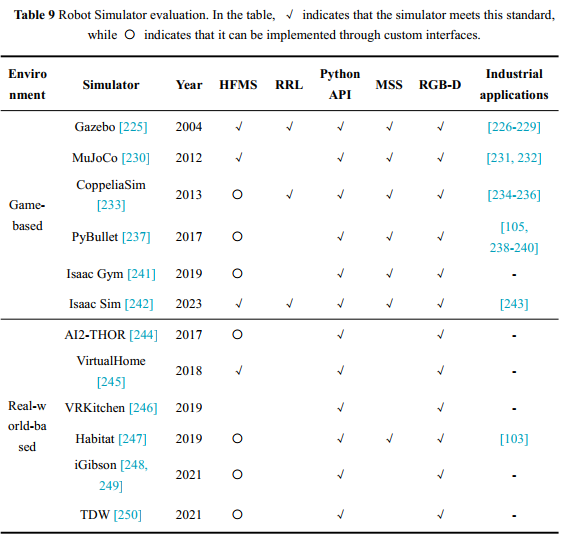
基于游戏的模拟器主要使用 3D 虚拟资源来构建环境,该环境由场景和对象组成,这些场景和对象由预先创建的 3D 模型组成。 此类模拟器的优点是资源需求低,场景构建速度快;因此,它们适用于对真实感要求不高的场景。
特别是在制造业,一般在设计阶段就获得各种设备和产品的 3D 模型,这些模型可以直接用于模拟环境的构建。 Gazebo[225] 是一个强大的开源仿真平台,它与 ROS 紧密集成,以支持高保真运动仿真。 它包括一个官方机器人库并提供多传感器支持;因此,它特别适用于工业环境中多机器人协作的仿真。 Mujoco[230] 以其高精度物理引擎而闻名,适用于机器人控制和强化学习任务。 其精确的动力学模拟使其在学术界得到广泛应用。 Pybullet[237] 是一个轻量级的物理引擎,适用于快速仿真和算法测试,特别是强化学习。 其简单的 API 和 Python 支持降低了用户门槛。 Isaac Sim[242] 提供多传感器系统的高保真运动仿真。 它基于 NVIDIA Omniverse平台,可提供全面的性能。 一般来说,这些模拟器可以为工业应用中的机器人运动、感知和任务执行仿真提供必要的功能和支持。 它们之间的差异主要反映在 HFMS 和 RRL 指标中。 如果应用场景侧重于与 ROS 的紧密集成,并且包含多机器人协作任务,那么 Gazebo 是一个理想的选择。 但是,Isaac Sim 具有更强大的物理仿真和复杂环境建模能力。 表 9 显示了 6 个基于游戏的模拟器的主要功能。 图 10 描述了这些基于游戏的模拟器的一些工业应用案例。
基于真实世界的模拟器通常根据真实世界的扫描数据构建模拟环境。 与基于游戏的模拟器不同,它们依靠 3D 扫描技术将现实世界的环境转换为数字模型;因此,它们提供了更高的真实感和更多的对象细节。 由于其高保真度,基于现实世界的仿真器通常用于需要更高仿真精度和Sim2real 迁移的应用场景;此类应用可能包括室内环境中的导航和交互。 表 9 显示了 6 个基于实际的模拟器。 评估结果表明,这类模拟器在作过程中一般使用人类作为智能体,不包含机器人库。 但是,它们拥有许多现实世界的 3D 资源,例如家具、家用电器和室内布局;因此,它们支持多智能体模拟交互。 例如家具添加,基于现实世界的模拟器通常缺乏工业制造场景中常用的传感器的支持。 这种缺乏使得这些仿真器难以满足工业自动化要求。 在这些模拟器中,只有 Habitat[247]提供了一定程度的 EIIR 模拟能力;因此,它是在基于实际世界的模拟器中工业机器人应用最具潜力的选择。
6.2 生产线模拟器
生产线模拟器主要用于模拟整个生产线的运行,而不仅仅是机器人。 与机器人模拟器不同,生产线模拟器侧重于多个设备、机器人、传感器、执行器和控制系统之间的协调;因此,它们比机器人模拟器更适合工业场景。 他们的软件通常集成了各种工业设备和机器人的控制器,可以模拟整个生产线的工作流程。 这些工作流包括各种流程,例如物料搬运和组装。 由于生产线模拟器已经有自己的机器人控制器和设备接口,因此它们不需要与 ROS 集成;相反,专注于工业自动化场景中设备协作的仿真。
由于这些特性,生产线模拟器的评估标准是与机器人模拟器不同。 例如,HFMS 指标不再关注是否与 ROS 集成;相反,它确定模拟器支持的机器人控制器的数量,以便可以评估适用的机器人品牌范围。 RRL 表示模拟器或官方网站上提供的机器人型号数量;因此,它反映了模拟器支持各种机器人模型的能力。 两个额外的评估指标,PLC 和 Multi-devices,也用于评估生产线模拟器;它们用于确定仿真器是否能够有效地模拟用于生产线控制的 PLC,并对多个设备之间的交互进行建模。 表 10 显示了使用上述评估指标的 10 个生产线模拟器的评估结果。 相关信息是从官方网站、说明、相关研究和案例博客中收集的。 但是,由于软件版本迭代更新,相关值和标准可能会发生变化。
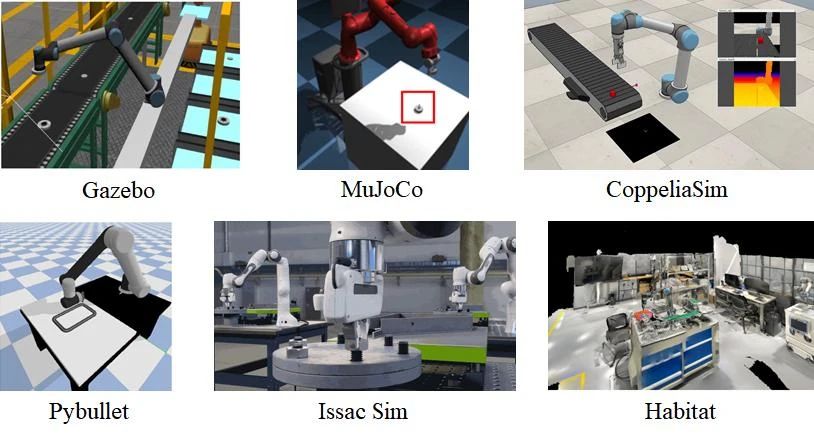
大多数主要的工业机器人制造商都为自己的机器人品牌开发了自适应工业模拟器。 例如,KUKA.Sim是一种专门用于 KUKA 机器人离线编程的模拟软件[251]。 该软件可以在设备投入运行之前在虚拟环境中显示机器人的运动,从而从节拍时间的角度实现运动优化。 它还通过可访问性检查和碰撞识别功能确保机器人程序和布局的可行性。 此外,由于该软件支持 MSS、PLC 和多设备交互,因此 KUKA.Sim 可以创建数字孪生;也就是说,场景与真实的生产线一模一样。 虚拟和真实控制系统使用相同的数据进行作。 因此,它能够在虚拟环境中测试和优化新的生产线,KUKA。 Sim 已成为虚拟调试的基础。 RobotStudio 软件[252],为 ABB 机器人开发的软件,以及为 FANUC 机器人开发的 ROBOGUIDE 软件[253],可以完成类似的功能。 但是,MotoSim 软件[254] 不支持与外部 PLC 的连接,并且无法完全模拟整个生产线的运行。 此外,EIIR 需要一个模拟器来支持机器人深度学习。 上述四个软件包可以直接或间接支持 Python API,便于与外部系统或深度学习模块集成。 然而,KUKA.Sim 和 MotoSim在模拟环境中不支持 RGB-D 相机;因此,机器人无法直观地感知其环境。 在生产线仿真和深度学习支持方面,RobotStudio的综合性能最佳。
图11.生产线模拟器的工业示例。这些数字是从文献或案例研究中获得的
综上所述,尽管现有的主流产线模拟器在工业设备集成和产线虚拟调试方面趋于成熟,但其当前状态与 EI 集成仍存在很大差距。 一方面,此类平台通常缺乏开放的 Python API 和可扩展的深度学习框架;因此,他们很难支持决策算法的训练和测试。 另一方面,他们用于真实物理交互的关键模块,如深度摄像头仿真和触觉反馈仿真模块,还不够完善;因此,代理很难在虚拟环境中获得近乎真实的传感器输入。 尽管 5.1 节中描述的机器人模拟器在单机器人深度学习训练和高保真数据采集中表现良好,但它们受到与 PLC 通信协议缺乏兼容性、MES 联动能力弱等多个问题的限制。 因此,他们无法构建包括传输线、传感器网络和其他元素在内的完整工业场景。 因此,在构建 EIIR 模拟器时,开发人员必须全面评估这两种类型的模拟器之间的差异。 产线仿真器可以先用精准的设备模型构建产线数字孪生基地,然后通过 ROS 或 OPC UA中间件接入支持深度学习的专用机器人仿真节点,最后形成一个兼顾工业设备保真度和智能体训练灵活性的复合仿真架构。
7 挑战和未来工作
根据本文第 3-6 节总结的EIIR 框架四个模块相关方法的发展现状和趋势,总结了 EIIR 技术在工业场景或系统中的应用方面未来研究的可能挑战和潜在方向。 这些摘要在以下小节中介绍。
7.1 工业世界模型
本文的作者认为,如果要在真实的工业场景中成功部署 EIIR,它应该具备三种最基本的知识: 通用知识、工作环境知识和操作对象知识。 现有的 LLM 在用于工业任务时容易出现“ 工业错觉” ;也就是说,结果在语义上似乎是正确的,但它们不能用于工业场景。 因此,迫切需要开发一种工业基础模型,该模型能够快速准确地管理与工业场景的整个生命周期[268]( 包括产品设计、制造、测试和维护)相关的任务。
关于可能的解决方案,由于工业场景和流程的复杂性,笔者认为应首先将工业基础模型分解为一系列领域基础模型,如装配、加工和产品设计的基础模型。 然后,必须设计一种机制,例如专家混合(MOE),以集成各种领域基础模型,从而形成最终输出。 预计,随着工业基础模型的发展,LLM 完成各种任务的能力应该达到甚至超过各个工业领域专家的能力。 在训练过程中,工业基础模型也会有大量来自工业场景的工作环境知识和操作对象知识,这些知识也可以用来赋能语义图谱和知识图谱的构建。
7.2 工业高层任务规划器
在工业场景中,工作环境知识和操作对象知识的缺失成为制约 EI 任务规划的核心障碍。 传统框架依赖于大型模型( LLM 或 VLA 模型)的一般知识,该模型可以解释自然语言任务并感知对象的位置。 然而,由于缺乏深入的工业知识(如 ISO 标准和工艺手册),任务分解结果偏离了工程约束( 装配步骤的顺序可能不正确或可能忽略了工艺要求)。现有工业方法的基于规则的系统是有限的,因为必须手动定义刚性逻辑;因此,适应柔性制造的要求是困难的。 基于学习的方法依赖于大量的注释数据,因此无法快速迁移到新的生产线。
因此,研究基于语义图谱和领域知识图谱的类 RAG 高级任务规划技术是当务之急。 语义图谱和知识图谱可以在结构上存储各种类型的知识,例如环境信息、零件参数和装配过程,并且可以约束大型模型的推理路径。 RAG通过实时检索外部知识库( 如流程文档、质检标准等),动态增强大型模型的领域认知。 这条集成路径有望克服现有框架的“ 知识盲区” ,实现从一般语义理解到产业确定性规划的转变。
7.3 工业低级技能控制者
首先,必须学习能够泛化工业数据的 EIIR 技能,例如开放词汇的工业对象检测。 为了降低工业客户使用 EIIR 技术的门槛,迫切需要具有更强泛化能力的工业数据感知技术。 采用“ 6D 姿态估计”(即
必须学习“ 测量” 技能)为例,大多数工业零件由一系列参数化零件组成;也就是说,这些零件基本上是使用各种参数值从参数模板实例化的,而参数模板的基元和基元之间的约束关系保持不变。 然而,现有的点云深度学习方法尚未找到此数据特征。 如果将此方法直接应用于工业数据,其性能会显著下降。 因此,深入研究二维[269]和三维工业数据[270,271] 的感知技术是非常必要的。 其他技能( 如“ 领料和放置”技能)也存在针对工业场景的类似要求。其次,还需要研究工业异构器件的通用低级控制语言。 在工业环境中,EI“ 身体” 不仅拥有单个机器人,而且还必须与由 PLC 驱动的其他设备合作。 但是,EIR 框架中现有的低级控制器仅限于 ROS,生成的标准化动作指令无法直接适配到工业控制器上;因此,多设备协作会产生“ 协议墙” 。 例如,对机器人的“ 抓取” 命令必须触发气缸夹紧动作,该动作由 PLC 同步控制;然而,ROS 和工业现场总线之间的时序差异很容易导致动作错位或安全风险。 为了消除这种差异,有必要构建一个工业 DSL,它可以作为代理和物理设备之间的中间链接。 DSL 的主要设计目标包括: 协议独立性,将指令动态编译为目标设备的本机控制语言( 例如用于机器人的URScript 和用于 PLC 的ST),从而实现跨品牌和跨类型设备的无缝连接;可扩展性,支持基于模块化架构的协议插件,适应性强,适应柔性生产线的快速重构需求。
7.4 工业生产线仿真器
现有的机器人仿真器( 如Gazebo 和 Isaac Sim)侧重于单个机器人的动态建模和运动仿真,而工业生产线必须实现涉及机械、电气、液压和控制多域耦合的系统级仿真。 现有的模拟器很难对这种跨域交互过程进行建模,这种困难导致虚拟调试结果与实际生产线条件之间存在重大偏差。 此外,虽然传统的工业生产线模拟器( 如 Tecnomatix 和DELMIA)可以构建高保真生产线数字孪生,但由于缺乏开放的深度学习接口,它们无法支持具身智能体的在线训练和策略优化。
为了满足多域耦合和智能体训练数据的双重需求,需要构建一个融合虚实域的 EIIR 模拟器。这个过程包括两个主要方向。 首先,应提出一个开源模拟器来支持虚拟工业代理的运行。 这个下一代模拟器必须克服单机器人建模的限制,构建一个开放的平台来支持工业场景中的单机器人和产线智能体,并支持智能体的快速部署。 通过开源社区协作,模拟器将能够集成多种工业控制协议,并将兼容 ROS 和深度学习
构建开放平台,支持工业场景框架中的单机器人和产线智能体,从而为工业智能体提供即插即用的培训环境。 其次,必须建立用于工业基础模型适配的仿真数据引擎。 根据大模型的训练需求,模拟器必须加强数据生成能力,通过参数化场景配置批量生成数百万个多样化的工况数据。 例如,它必须生成机器人轨迹、视觉、触觉和力感应数据。 根据上面讨论的高保真多模态训练数据,可以形成一条“ 设备级物理保真 → 产线级逻辑验证→ Agent 策略优化” 的闭环路径。
8 结论