

Cailyn
生成式 AI 的爆发式发展正在重塑全球科技格局。
OpenAI 的 GPT-4 训练需 2.5 万张 A100 GPU 耗时 100 天,而 GPT-5 预计需 5 万张 H100 GPU,训练成本超百亿美元。
Meta 计划新增 35 万张 H100 GPU,资本支出提升至 400 亿美元,这背后是算力需求的指数级增长 — 自 2012 年以来,AI 大模型训练算力每 3.4 个月翻一倍,2020 年模型算力需求达 2012 年的 600 万倍。
当万卡集群成为大模型竞赛的 “入场券”,十万卡集群正成为科技巨头竞逐的新高地。
xAI 的 Colossus 集群在 122 天内建成 10 万张 H100 GPU 集群,腾讯基于星脉网络支持 10 万卡 GPU 计算规模,阿里云灵骏集群拓展至十万卡级别。
这些突破不仅是算力规模的跃升,更是 AI 基础设施从 “量变” 到 “质变” 的里程碑。
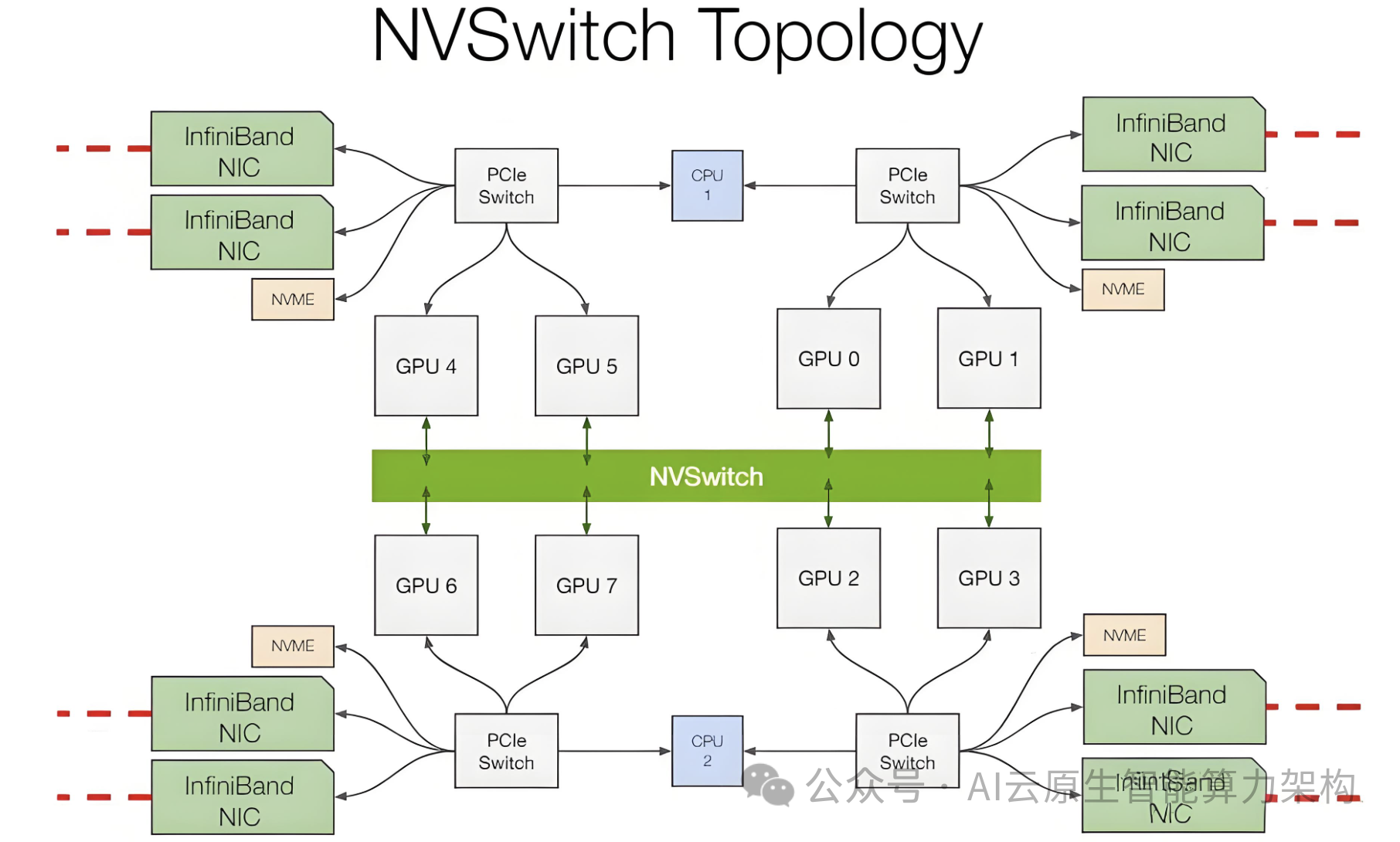
二、十万卡集群的技术挑战:从物理层到软件栈的极限突破
1. 硬件层:高密度部署的 “不可能三角”
网络瓶颈:十万卡集群需 TB 级 / 秒带宽和毫秒级延迟,传统以太网难以满足。xAI 的 Colossus 集群采用英伟达 H100 GPU 和液冷系统,通过定制 RDMA 网络实现节点间低延迟通信,但调试过程中遭遇 BIOS 不匹配、网卡故障等问题,凌晨 4 点仍在排查网络电缆。
散热与供电:单张 H100 功耗达 700W,十万卡集群总功耗超 70MW,相当于 7 万户家庭的用电需求。xAI 租用美国四分之一的移动冷却能力,改造废弃工厂并引入特斯拉 Megapack 储能系统,通过重新编程应对电力波动。腾讯 HCC 集群采用冷板式液冷技术,PUE(电能使用效率)降至 1.1 以下。 异构兼容:国内企业需混合使用国产 GPU 与英伟达芯片。百度百舸 4.0 支持异构芯片调度,通过显存优化技术提升训练效率 30%,而阿里云灵骏集群实现 99% 以上的连续训练有效时长。
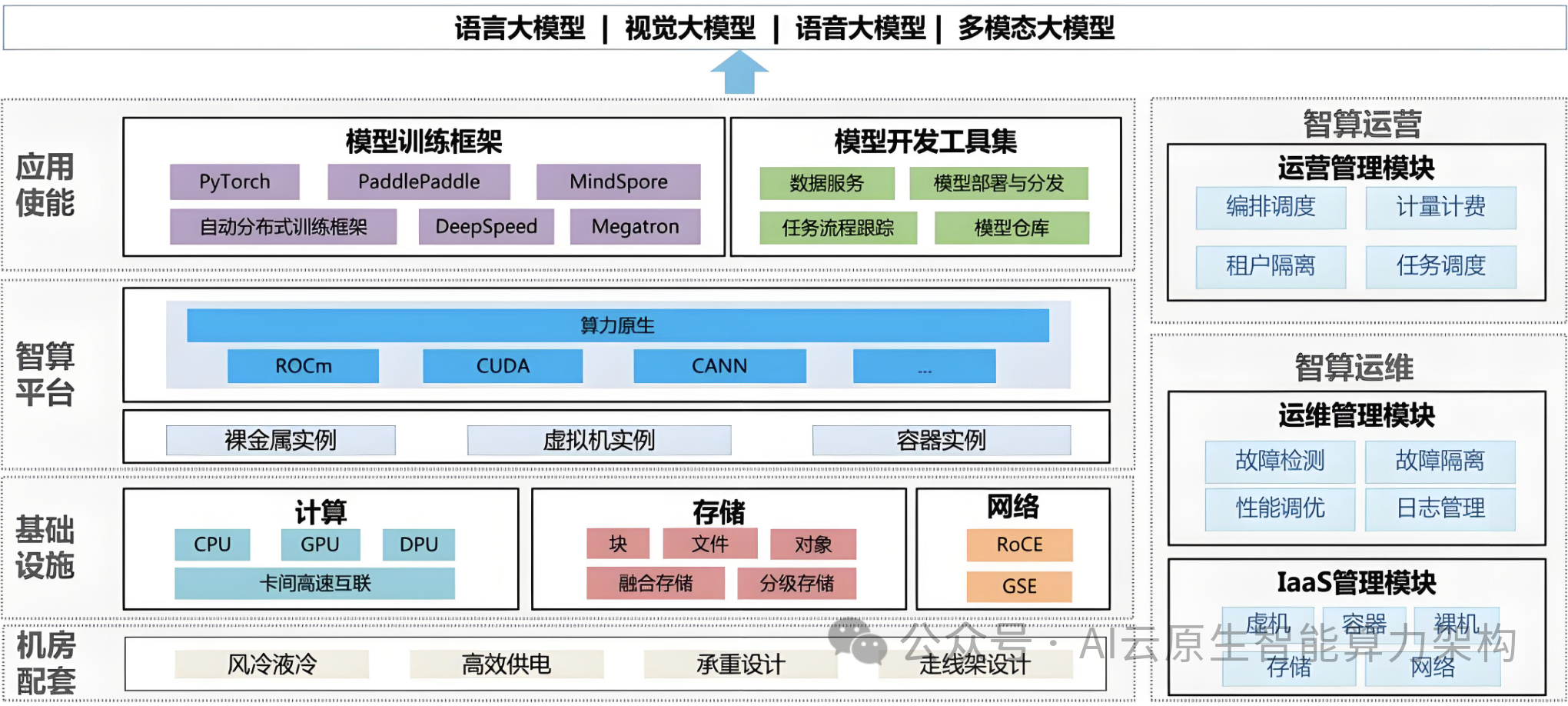
2. 软件层:分布式训练的 “熵增困境”
并行范式突破:传统数据并行和模型并行在十万卡规模下遭遇通信瓶颈。OpenAI 训练 GPT-4.5 时,10 万卡集群暴露基础设施隐藏故障,系统团队边修边训,最终将算力利用率提升至 60%。腾讯 Angel 平台采用混合并行策略,训练速度达主流框架 2.6 倍。 容错与调度:Meta 训练 Llama3 时,1.6 万卡集群每 3 小时故障一次,需回滚至检查点。百度百舸 4.0 通过自动弹性训练和分布式容错技术,将有效训练时长占比提升至 99.5%。 异构资源管理:锐捷网络与燧原科技合作开发 AI-Fabric 解决方案,通过 RoCE 交换机实现 97% 带宽利用率,支持十万卡集群的异构芯片协同。
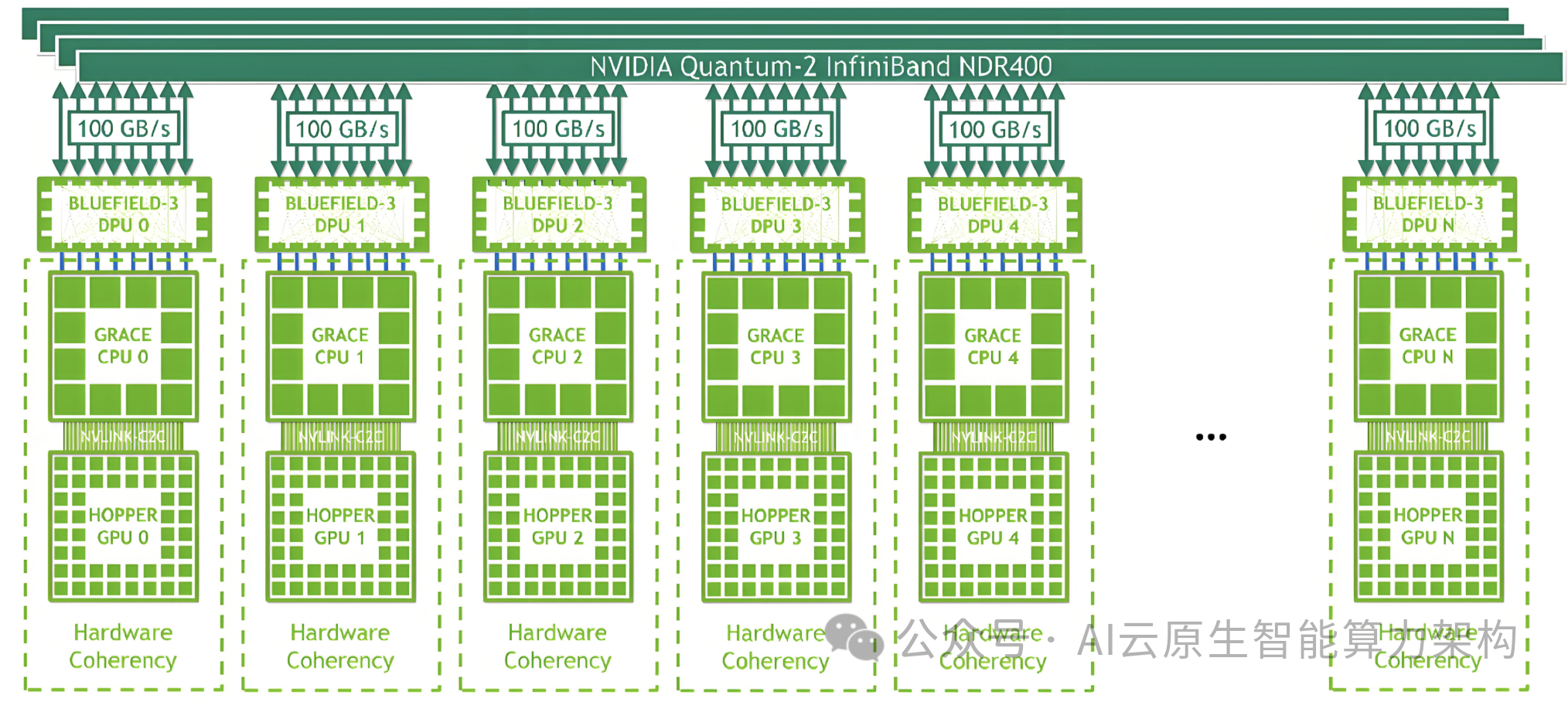
三、破局之道:集成、网联、分布式的 “质量双螺旋”
1. 硬件持续集成:从芯片到系统的能效革命
芯片级创新:英伟达 H100 采用 NVLink 4.0 技术,单卡互联带宽达 900GB/s;国产昇腾 910B 通过全互联架构提升算力密度。 液冷系统普及:xAI 的 Colossus 集群采用液冷技术,将 PUE 降至 1.05 以下;华为推出冷板式液冷方案,支持单机柜 50kW 高密度部署。 电力模块重构:华为融合极简电力模块实现 “边 - 端” 协同供电,提升供电效率 15%。
2. 高性能网络互联:构建算力高速公路
端网协同优化:腾讯星脉网络 2.0 采用自研 TiTa 协议,支持 3.2TB/s 带宽和 10 万卡组网;锐捷网络 AI-FlexiForce 方案通过 400G LPO 光模块降低功耗 30%。 拓扑架构创新:阿里云灵骏集群采用三级 Clos 网络拓扑,支持跨地域集群互联,网络时延降至 2 微秒。 智能运维:锐捷网络 AIGC 量化分析平台实时监控网络状态,故障定位时间从小时级缩短至分钟级。
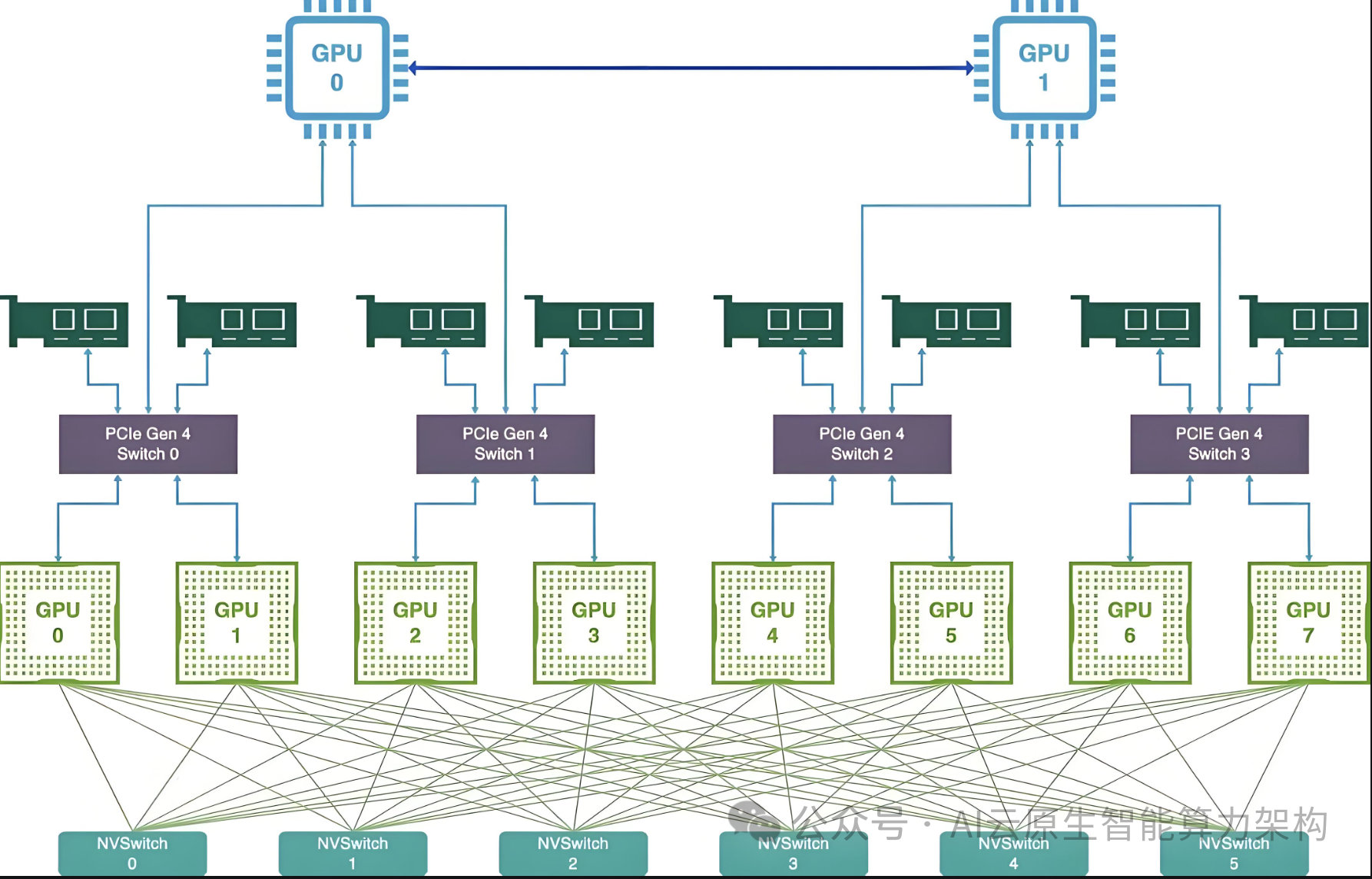
3. 分布式训练优化:释放算力潜能
训练框架革新:阿里云 PAI-DeepRec Extension 通过自动弹性训练和资源预估,节省 20%-60% 算力资源;腾讯 Angel 支持千亿参数模型的分布式训练,显存利用率提升 40%。 任务调度智能化:百度百舸 4.0 引入 AI 驱动的任务调度算法,动态分配算力资源,训练效率提升 30%。 多集群协同:OpenAI 探索多集群协作训练,未来或涉及千万级 GPU 规模,需突破跨集群容错技术。
四、行业实践:从实验室到产业落地的跨越
1. 科技巨头的 “超级工厂”
xAI Colossus 集群:10 万张 H100 GPU、液冷系统、特斯拉 Megapack 储能,122 天建成全球最大训练集群,支撑 Grok 3 的推理能力提升 10 倍。 腾讯 HCC 集群:基于星脉网络和液冷技术,支持 10 万卡 GPU 计算规模,MFU(算力利用率)达 65%。 阿里云灵骏集群:单网络集群拓展至十万卡级别,模型算力利用率提升 20%,支撑通义千问大模型训练。
2. 行业应用标杆
制造业:华为与车企合作,构建十万卡集群支持自动驾驶模型训练,将训练周期从 3 个月缩短至 2 周。 生物医药:药明康德利用十万卡集群加速蛋白质结构预测,单日处理数据量突破 10PB。 金融风控:蚂蚁集团通过分布式训练框架优化反欺诈模型,误报率降低 40%,响应时间缩短至毫秒级。
五、未来展望:可持续计算与技术范式变革
1. 绿色算力新范式
可再生能源整合:华为推动 “源网荷储” 一体化,引入西部风电和光伏,实现绿电直供。 碳足迹追踪:阿里云推出 “绿色算力认证”,量化每千卡算力的碳排放,推动行业低碳转型。
2. 技术范式突破
存算一体架构:寒武纪 MLU370-X8 采用 HBM3 内存,减少数据搬运能耗 50%。 神经形态计算:IBM TrueNorth 芯片模拟人脑神经元结构,能效比达传统 GPU 的 1000 倍。
3. 算网融合生态
算力网络 3.0:中国移动构建 “东中西” 泛在算力布局,实现跨域资源调度和智能编排。 开源协同:Meta 开源 LLaMA 3 训练代码,推动十万卡集群技术普惠。
六、结语:重塑 AI 时代的算力底座
十万卡 GPU 集群不仅是算力规模的跃升,更是 AI 基础设施从 “工具” 到 “基座” 的质变。它标志着 AI 发展进入 “超级工业化” 阶段 —— 通过硬件集成、网络互联和分布式训练的深度协同,将算力转化为通用生产力。随着液冷技术、存算一体架构和绿色算力的普及,十万卡集群将成为数字经济的 “电力系统”,支撑生成式 AI 从实验室走向千行百业,开启智能时代的新纪元。