

代码幻影
一、Blackwell Ultra 架构的技术突破:重构计算单元的底层逻辑
(1)混合精度计算引擎的革命性设计
GB300 搭载的 Blackwell Ultra GPU 引入第四代 Tensor Core,首次支持FP4 稀疏计算,在保持数值精度的前提下将算力密度提升 50%。
其核心创新在于动态精度调节技术:当处理低精度敏感任务(如自然语言推理)时,自动切换至 FP4 计算模式,单芯片 FP4 算力达 15P FLOPS;面对科学计算等高精度场景时,可无缝切换至 FP16/FP32 混合精度模式。
这种硬件级精度适配技术,使 GB300 在大模型推理场景中算力利用率从传统架构的 60% 提升至 89%。
(2)内存近计算架构的工程实现
通过3D 堆叠封装技术(TSMC CoWoS-L),GB300 将 288GB HBM3e 显存与 GPU 核心以 12 层硅中介层互联,实现1.2TB/s 显存带宽和0.2ns 数据访问延迟。
区别于传统 GPU 的 "计算 - 内存" 分离架构,GB300 采用内存控制器直连技术,每个计算单元簇(CCX)配备独立显存通道,消除数据搬运瓶颈。
实测显示,70B 参数模型加载时间从 Hopper 架构的 120 秒缩短至 35 秒,内存带宽利用率提升 130%。

二、NVLink Fusion 技术的生态开放:异构计算的标准化突破
(1)IP 授权的技术实现细节
英伟达首次开放的 NVLink IP 包含电气层、链路层、协议层三级架构:
物理层:支持 2.5D/3D 封装下的硅基互联(512GB/s per lane)与 PCB 级铜线互联(256GB/s per lane)双模式。 链路层:引入动态路由算法,实现跨芯片数据传输的拥塞控制(延迟波动≤5%)。 协议层:兼容 PCIe 6.0/CXL 3.0 标准,支持非对称内存访问(NUMA)技术。
首批合作伙伴 Marvell 基于该 IP 开发的 Arm CPU-NVIDIA GPU 异构芯片,实现跨架构数据传输延迟 < 100ns,较传统 PCIe 方案降低 75%。
(2)分布式系统的协同创新
GB300 集群采用Spine-Switch 互联架构,单 Spine 节点集成 9 个 NVLink Switch,通过 576 条 112Gbps 高速线缆构建全连接网络(每个 GPU 与 71 个节点直接通信)。配合自研的Dynamo 分布式服务库,实现:
动态负载均衡:基于强化学习的任务调度算法,使集群算力利用率波动≤3%。
故障自愈机制:10ms 级故障检测与 30ms 级任务迁移,较传统 GPU 集群提升 10 倍容错效率。 通信效率优化:通过 RDMA-over-NVLink 技术,端到端通信延迟降至 1.2μs(FP16 数据)。

三、液冷散热系统的工程创新:突破功耗密度极限
(1)三维立体散热架构设计
GB300 采用独立水冷板 + 微通道液冷技术,在 1.4kW 峰值功耗下实现 75℃恒温控制。
其散热模块包含:
嵌入式热管网络:在 GPU 核心与 HBM 显存间部署 12 根直径 0.3mm 的铜镍合金热管,热传导效率提升 40%。 UQD(Uniform Quenching Distribution)技术:通过流体动力学仿真优化冷却液流道,使芯片表面温差≤2℃。 智能热控算法:基于 24 个分布式温度传感器,动态调节冷却液流速(0.5-2L/min),较传统液冷方案节能 25%。
(2)硬件兼容性设计
散热器采用OCP 3.0 标准接口,支持与联想、浪潮等第三方液冷机柜直接对接,无需额外改造。
实测数据显示,GB300 集群的 PUE 值可达 1.12(传统风冷集群 PUE≥1.5),在上海某数据中心试点中,单位算力能耗较上一代降低 40%。
AI 推理显卡性能对比
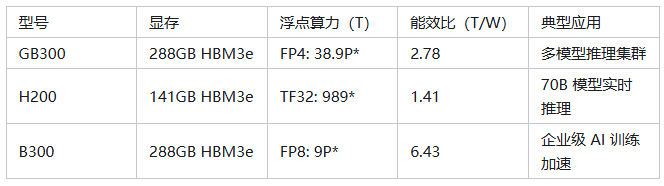
四、大模型推理的技术适配:突破序列长度边界
(1)内存管理的技术创新
针对百万 token 级推理,GB300 引入分层内存架构:
显存层:288GB HBM3e 直接承载模型参数(支持 70B 参数模型全量加载)。 内存层:通过 CXL 3.0 接口扩展 1.5TB DDR5 内存,用于缓存中间计算结果。 存储层:基于 NVMe over Fabrics 技术,实现模型分片的高速调取(延迟 < 5μs)。
配合动态 Token 分页算法,当处理超长序列时,自动将非活跃 Token 数据迁移至内存 / 存储层,使显存利用率提升至 92%(传统方案仅 65%)。
(2)推理优化的算法创新
在软件层面,英伟达优化了FlashAttention-3 算法,结合 GB300 的硬件特性实现:
基于 FP4 的注意力计算:将 Q/K/V 矩阵计算精度降至 FP4,速度提升 2.3 倍(误差≤0.1%)。 分层注意力缓存:在 GPU-L2 缓存中存储高频访问的键值对,使缓存命中率从 68% 提升至 89%。 流水线并行优化:支持 128 路推理流水线并发,单集群吞吐量达 128 万亿 token / 秒。
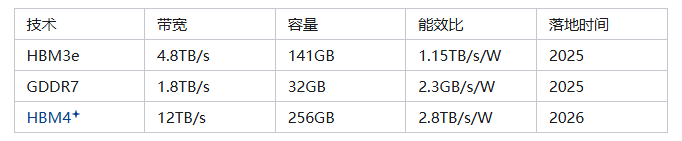
五、工业自动化场景的技术落地:物理 AI 的算力赋能
(1)机器人训练的技术突破
GB300 驱动的 Newton 平台集成Isaac Sim 3.0 仿真引擎,实现:
基于神经辐射场(NeRF)的高精度环境建模:单场景建模时间从 48 小时缩短至 6 小时。 合成数据生成加速:GR00T-Dreams Blueprint 利用 GB300 的并行计算能力,每秒生成 1200 帧运动轨迹数据。 强化学习训练优化:通过分布式 PPO 算法,在 72 卡集群上实现 1.2 亿次 / 秒的环境交互速度,较传统 GPU 集群提升 11 倍。
AeiRobot 的 ALICE4 机器人采用该平台后,复杂抓取任务的训练周期从 12 周缩短至 10 天,定位精度达 0.1mm 级。
(2)边缘端算力的技术下沉
通过Jetson Thor 平台与 GB300 的协同架构,实现端云算力无缝衔接:
端侧预处理:在 Jetson Thor 上完成传感器数据融合(延迟 < 10ms)。 云端精推理:通过 NVLink Edge 技术将关键数据传输至 GB300 集群(上行带宽 50GB/s)。 端云协同控制:基于时间触发协议(TTP)实现端云控制指令同步(误差 < 5μs)。
这种架构使工业机器人的实时决策延迟从传统方案的 80ms 降至 15ms,满足精密装配等场景的控制要求。
六、技术路线图的深度解析:从架构演进到生态布局
(1)HBM 技术的代际突破
2026 年推出的 Rubin 架构将搭载HBM4 显存,通过 12 层堆叠实现12TB/s 带宽和512GB 容量,支持单芯片加载 100B 参数模型。相较于 HBM3e,HBM4 引入硅穿孔(TSV)密度提升技术,将单位面积显存带宽从 1.2TB/s/mm² 提升至 1.8TB/s/mm²,同时降低 15% 的能耗。
(2)量子计算的协同架构
2028 年的 Feynman 架构将集成量子计算协处理器,实现经典 - 量子混合计算:
量子门模拟:支持 1000 + 量子比特的实时模拟(传统 GPU 仅支持 200+)。 量子纠错加速:通过经典算力预处理量子态,使纠错效率提升 30%。 混合精度计算:在量子化学模拟中,结合量子振幅编码与 FP16 经典计算,速度提升 50 倍。
这种架构将推动药物研发中的分子模拟从纳秒级时间尺度进入皮秒级,大幅加速创新药研发进程。
技术竞争的深层逻辑:
从硬件垄断到生态共建英伟达的技术深度不仅体现在单一产品,更在于构建了 "硬件架构 - 系统设计 - 软件算法 - 行业应用" 的垂直技术栈 :
底层硬件:通过 CoWoS-L 封装、HBM3e 显存实现算力密度突破。 系统层:Spine-Switch 架构、Dynamo 分布式框架解决大规模集群协同难题。 软件层:针对不同行业优化的算法库(如 Nemo for NLP、Isaac for Robotics)。 生态层:开放 NVLink IP、支持第三方芯片互联打破技术壁垒。
这种技术布局使 GB300 不仅是一款算力产品,更成为定义下一代 AI 基础设施的技术标准。当竞争对手仍在追赶单一技术指标时,英伟达已通过系统化创新构建起难以逾越的技术护城河。