

智造百科
虽然说方法论在工业大数据的重要性,不及业务行业理解那么重要,但是对于方法论的理解,尤其是澄清对于一些细节的误解,对于行业新人来说,也是至关重要的。
CRISP-DM,Cross-Industry Standard Process for Data Mining,是一个SPSS,戴姆勒等公司合作制定的一个跨行业数据挖掘标准流程。
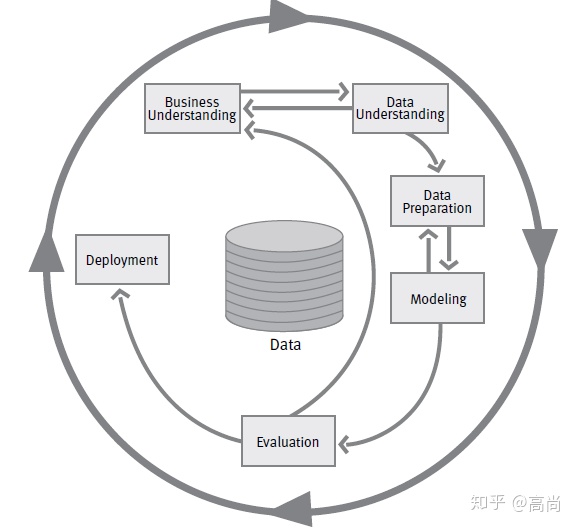
一个在跨行业(比如制造业)中的数据挖掘过程,大概是有六个阶段:
业务理解
数据理解
数据准备
建模
评价
部署
各个阶段任务大概如下:
第一阶段业务理解:从业务的角度理解项目的目标和需求,将业务的目的转换为一个数据挖掘的问题,制定一个初步的实现计划
第二阶段数据理解:初步收集数据,了解、熟悉数据。关注数据质量,进行探索性的分析。
第三阶段数据准备:准备最终输入到模型中的数据,数据的选择,数据清晰等
第四阶段建模:一般使用多种技术进行建模,将模型调整到最佳状态。
第五阶段评估:到这个阶段一般已经有从数据角度来看满足要求的模型。重点是评估是否有业务问题还没有考虑到,是否已经完全满足业务要求。评估数据挖掘结果的使用可能性。
第六阶段部署:数据分析完成了但是还不是最后一步。最后一步的部署可能是生成一个报告,也可能是需要建立一个整个公司层面的新的系统,这是看业务的需求来定。一般数据分析师不会主要来负责这一部分工作,但是一定要保证数据分析的结果被正确的使用。
在一个企业的数据挖掘项目中,各个阶段都有很多需要注意的问题。以下内容参考昆仑数据。
一、业务理解阶段
工业数据分析常常是一个知识严重二分的情形。数据分析师对工业过程缺乏深入了解,而业界人员对数据分析的了解相对缺乏,沟通成本很高,造成效率低甚至结果达不到预期。
有几种方法可以提高这样的情况下的沟通效率:
系统上下文(System Context)
业务方面要给出明确的系统上下文,包括业务相关(比如生产制造工程中,周围环境)等的相关原理、相关运作机制,相关关键信息,而且在尽量容易理解的同时,保证对于业务相关所有量的一个准确描述。
系统动力学模型(System Dynamics)

这个模型的核心,就是把业务相关的因素的数据,定义好自变量、因变量以及这些量的状态,是否可以观测,是否实时获得,是否可以控制等。
业务用例(Use Case)
要把一个工业大数据分析的项目需求描述清楚,就一定要定义好谁来用,什么时候,在什么情况下,如何使用,期待的结果是什么。
而且对于业务的需求一定要有重点以及突出优先级,对于期待的结果一定要有量化的衡量。比如判断一个机器状态是否正常,想要达到的程度,是要寿命预测,实时监测、异常通知,或者需要提前一个时间段预警,可能代表的是完全不同的业务难度。
比如,对于风机发电机结冰问题,结冰预测需要小尺度的天气预报,若做到风机层面的预测还需要叶片表面光洁度等信息(否则,解释不了平原风场的3台相邻的风机,只有1台结冰,另外2台没有结冰的现象,这3台风机同型号同时期建设,地形和周边环境也几乎一样)。但做到结冰检测基于SCADA风机状态数据就可以做得比较准确。从业务用例分析来看,风场运维需要是:能在风机严重结冰前采取适当措施,避免高载荷下运行对风机造成损害。及时的结冰检测报警也可以满足业务需求。(K2Data)
这几种方式,核心都是减轻知识相互不对等的两方合作时候,交流的成本。对于一个企业来说,建立一个长期的、渐进的培训学习机制,可以有效的提高这样的交流效率。
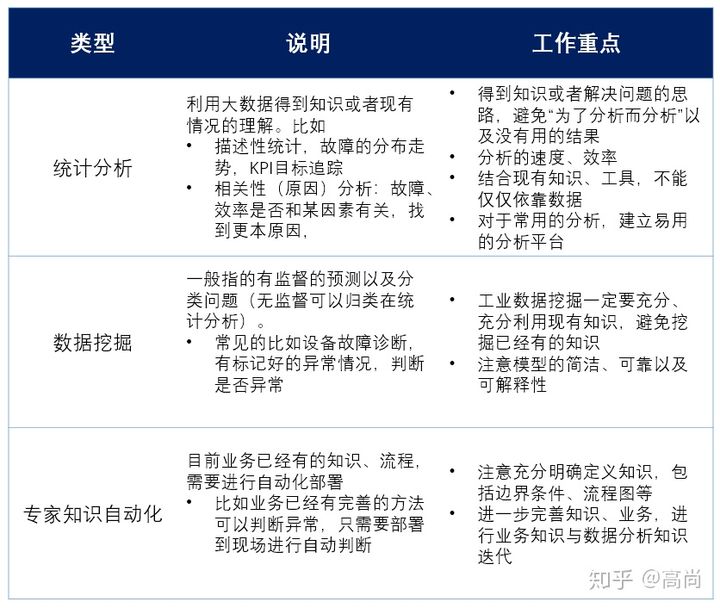
最后,业务方面的需求大概可以分为如下三类:
二、数据理解阶段
数据理解阶段,包括审查现有的数据,对数据进行第一阶段的初步洞察。最终回答的核心是这样的一个问题:
数据挖掘大概可以看成这样的一个情况。
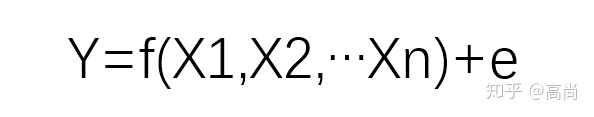
我们现在有很多数据x,以及因变量Y,想要找到一个f,在可以接受的错误e的情况下,满足这个关系。
实际关系是有很多的X,也有很多的Y,关系复杂。但是我们可以考虑到的、测量的、可以收集的总是比实际少的,大概是这样的关系。
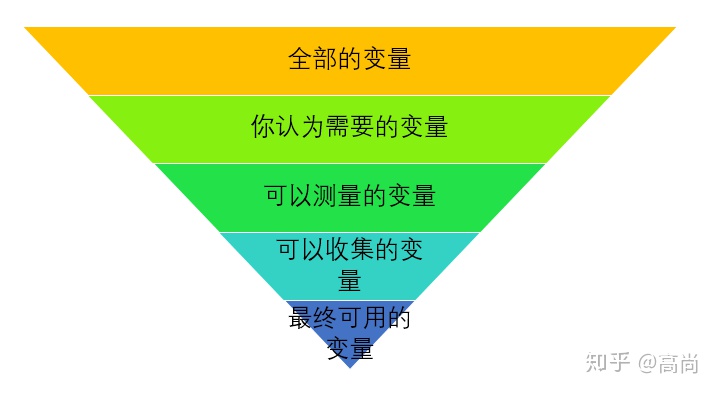
这时候就要看一个问题,经常是这样的:
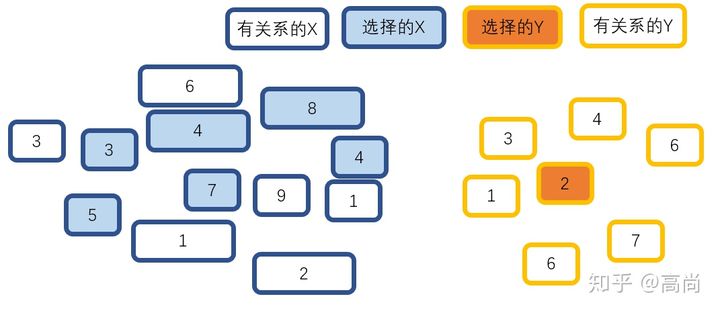
实际中会有很多的量,但是我们可以获取的,只有一部分。核心的问题就是:这样的数据,有没有能力可以实现我们的目标。
还有就是数据分析的根基:数据质量
这个数据质量,在本身的以数据的方法判断之外(比如缺失值,明显的离群值等等),还有一些在工业领域一定要注意的事情。
有些工业领域的数据,如果不是直接采集,而是人工收集的,可能需要更多的时间去判断是否合理,需要结合情境,比如为了满足KPI而人为修改的效率数据。就算是机器直接收集的,也要考虑比如在某天产量极低的情况下,反而故障很高,是否是工厂在调试维修状态。比如机器状态在正常的情况下,用电量反而极低,是否是机器核心功能已经停止但是并没有及时报错等等。
这个阶段,就像大楼的地基一样,如果在项目的靠后阶段才发现问题,将会浪费大量的时间。所以对于关键性的数据,一定要结合多方面的知识来审核。
数据成本:数据分析师的进退两难
在传统的制造企业,数据分析师往往是一个比较新的部门或岗位,虽然级别低,但是经常要调动非常多的资源。这就带来了一个困境,经常会有数据较难获取的情况。
而且在很初期的阶段,数据分析师也很难在进行初步分析之前,就预测项目的成果。对于一些数据分析贯彻不够坚决的地方,数据分析师往往是巧妇难为无米之炊。
但是很多时候也会有另外一个极端,分析师战略地位足够高,业务部门足够配合,这时候分析师对于数据的需求,直接决定了这个阶段的工作量。如果一味的追求高质量、大量的数据,可能对业务造成极大的负担。
三、数据准备阶段
前边提到的数据获取等,也可以归纳到这个阶段。
个人更偏向于这个阶段开始已经是分析师的工作量大于业务方面。
这个阶段主要任务:
原始数据抽取,转换等纯数据的加工
结合前期对数据的理解,最终完成数据清洗
特征提取
这是这个阶段最重要的事情,到了项目的后期也经常会再回到这个点进行进一步的工作。
还是一样,在工业领域,一定要一定要一定要利用现有的知识,首先充分利用现有的知识进行特征提取。在相对成熟的领域一般都已经有现成的解决方案、论文等可以参考。
可以说这个阶段,直接决定了项目是不是可以成功。
第三阶段的工作往往要占到整个工作时间的40%以上。
第四阶段、建模
机器学习建模的过程。机器学习建模的方法目前已经很成熟稳定,在工业界使用的一般也是相对简单、稳定,研究了很多年的模型。这些模型已经足够优秀来解决工业界的问题。
这部分工作对于机器学习研究者、互联网从业者来说往往会显得很低级和无聊,工作占整个项目的工作量,在一个普通的项目里大概5%不到。
有足够质量的数据、优秀的特征以后,现在的建模也不需要你写代码了,大量的分析工具都可以很简单快速的完成常用模型。剩下还有非常大量的时间用来解释结果、汇报、不熟等等。
结合前边表格中的工作重点,这部分需要注意的问题主要还是两个:
充分利用现有的知识
模型简单、可靠,可解释性高
第五阶段、评价
在有一个从数据角度来说可用的模型以后,这个阶段再回到业务的角度来审核模型。毕竟制造业还是以人的决策为主。
这个阶段尤为重要的是审核模型应用的风险,比如是否有模型不可用的例外情况,模型应用的边界是什么样的。这个阶段的结果直接决定了数据分析是否能落地,往往很多数据分析的项目,在这一阶段不能说服业务方和管理者,也就不能实现价值。
这个阶段还有一个重要的评价是部署的方案。方案的成本、最终的收益、可扩展性、带来的风险等等,经过这些综合的考虑如果方案可以带来的直接、间接的经济收益大于支出和风险,那么就可以看做项目已经成功,就只待最后部署。
第六阶段、部署
对于上一个阶段部的策略进行实施。并不是一定要上一套新的大数据平台才算作是成功的部署。一个业务流程的改进,可能是通过人工的数据收集、通过相对简陋的分析系统手动分析、反馈结果给业务部门使用,这有时候可能也是一个非常好的结果。
这个阶段要注意的是对于全流程的清晰定义以及维护,进一步积累知识。
结束
在整个CRISP-DM的过程当中,围绕数据为核心,项目可能会在各个阶段之间跳跃,因为数据分析一定是一个不断迭代的过程。
CRISP-DM中定义了各个阶段要做的工作以及典型的交付物,非常值得学习一下。