
工业引擎
从 DNA 的发现到对各种生物进行基因测序,「DNA 到 RNA 再到蛋白质」的「中心法则」一直是生命科学的核心原则。这三种承载信息的生物聚合物承担着细胞内的大部分工作,进而决定了各种生物体的结构、功能和调控。
今天的故事就从「中心法则」开始。还记得去年 6 月 ScienceAI 报道过的开源生物大模型「LucaOne」吗?不记得也不要紧,现在带大家复习一下。
LucaOne 是首个联合 DNA、RNA、蛋白质的生物大模型,由中山大学施莽、阿里云李兆融领导的联合研究团队开发。该模型旨在综合学习遗传和蛋白质组语言,涵盖 169,861 个物种的数据。
该模型不仅可以对核酸、蛋白质的内部特征进行挖掘,还可识别核酸与蛋白质之间的联系,可以帮助研究人员探索更多生物系统的内在逻辑与规则。
时隔一年,这项研究以「Generalized biological foundation model with unified nucleic acid and protein language」为题,于 2025 年 6 月 18 日刊登在了《Nature Machine Intelligence》杂志。

LucaOne 的核心亮点在于其独特的自监督加半监督学习架构,该架构基于生物语言的本质属性设计,使得模型能够在 10 亿量级的序列与注释信息上进行学习,参数规模约 1.8 B。
让我们简单看一下 LucaOne 是怎样工作的。
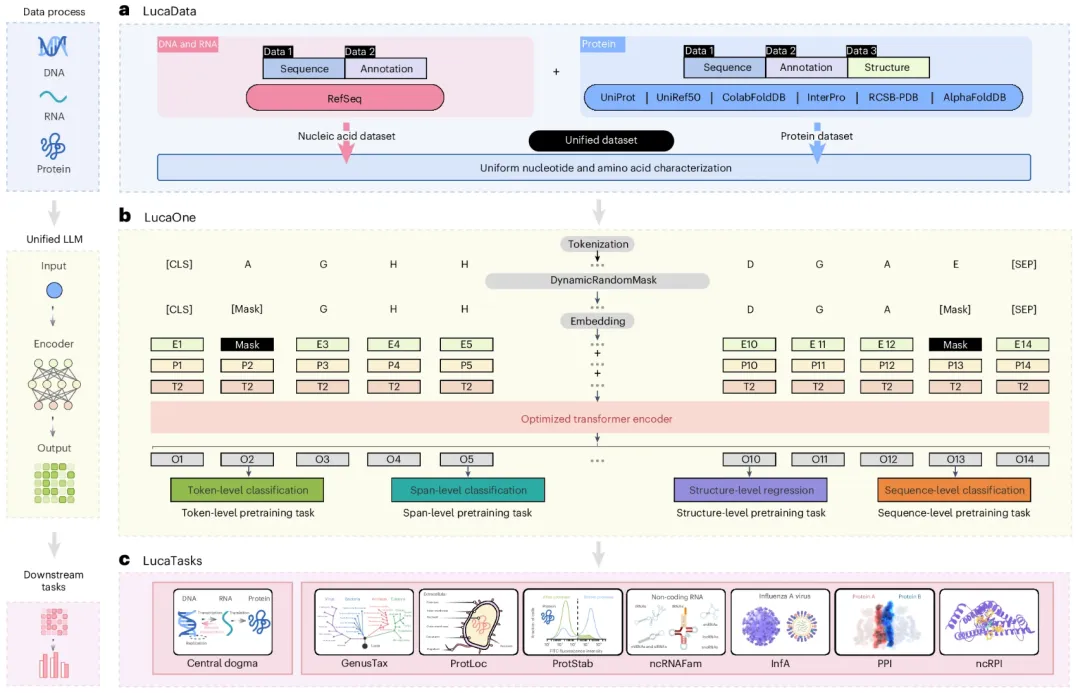
图示:LucaOne 的工作流程。(来源:论文)
宏观层面
相比于其他面向单类型数据的生物大模型 [DNA(如 DNABert2、EVO)、RNA(如 UniRNA)、蛋白质(如 ESM2)],LucaOne 是第一个面向生物学「中心法则」的这三种类型数据的基础大模型。从 DNA 转录成 RNA 再翻译成蛋白质,这些数据本身具有内源性,所以放在一起建模是合理的。
现有模型的只对序列进行自监督建模(序列的 mask 任务或者下一个 token 预测),LucaOne 是第一个将生物领域内大量的基础并通用的标签信息加入预训练阶段,让模型能够学习到足够多的信息,从而表征能力足够强大且通用。
「这个模型目标是希望学习生物系统的底层编码,目前这个版本以基因组、转录组、蛋白质组为核心。其中的核苷酸及氨基酸序列是生物系统里的两种模态,放在一起统一学习能帮助模型更快学习到生物系统的编码体系。」去年这个项目开源时,这项研究的负责人李兆融对媒体解释道。
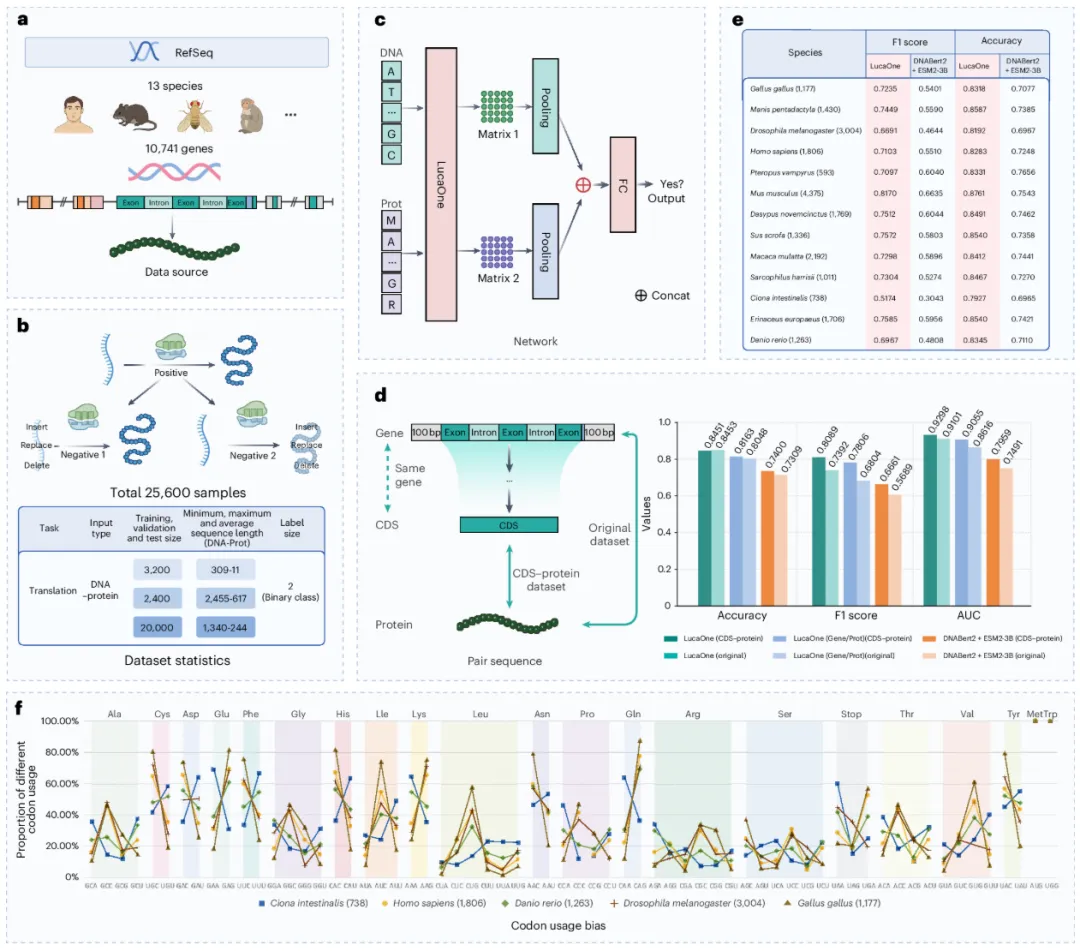
图示:分子生物学中心法则任务的工作流程。(来源:论文)
微观层面
LucaOne 使用的是 Transformer-Encoder 架构,在此基础上进行了一些局部设计,包括:
a. 将 DNA,RNA 与 Protein 的 Token 统一起来;
b. 除了本身的序列自监督学习,增加了 8 个基础性的半监督学习任务,避免只对序列学习的不足问题(区别于文本,人类认识通过注释这些分子本身不存在的标签信息来认识与理解这些自然界语言的);
c. 多个半监督学习任务如何融合以及半监督信息的假阴性如何容错;
d. 增加分子类型编码与改进位置编码等。
「这里我们考虑的是生物序列的信息密度,虽然不能这样武断的说,但是大致上基因组的信息密度是低于文本信息的,并且可能分布不均。比如,生物序列里可能会存在一些无意义片段,且片段非常长;应对这类问题,我们需要一些取巧的方式。」李兆融曾经表示,「因此,在我们设置了 8 个有监督的任务,这使得模型更有效的进行学习。」
「模型的参数有 1.8 B,什么概念呢?我们希望模型既足够「大」,能理解复杂生物系统,又不至于太大影响下游的使用效率。在整理高质量数据后,我们将模型参数设置在这个级别。」
性能
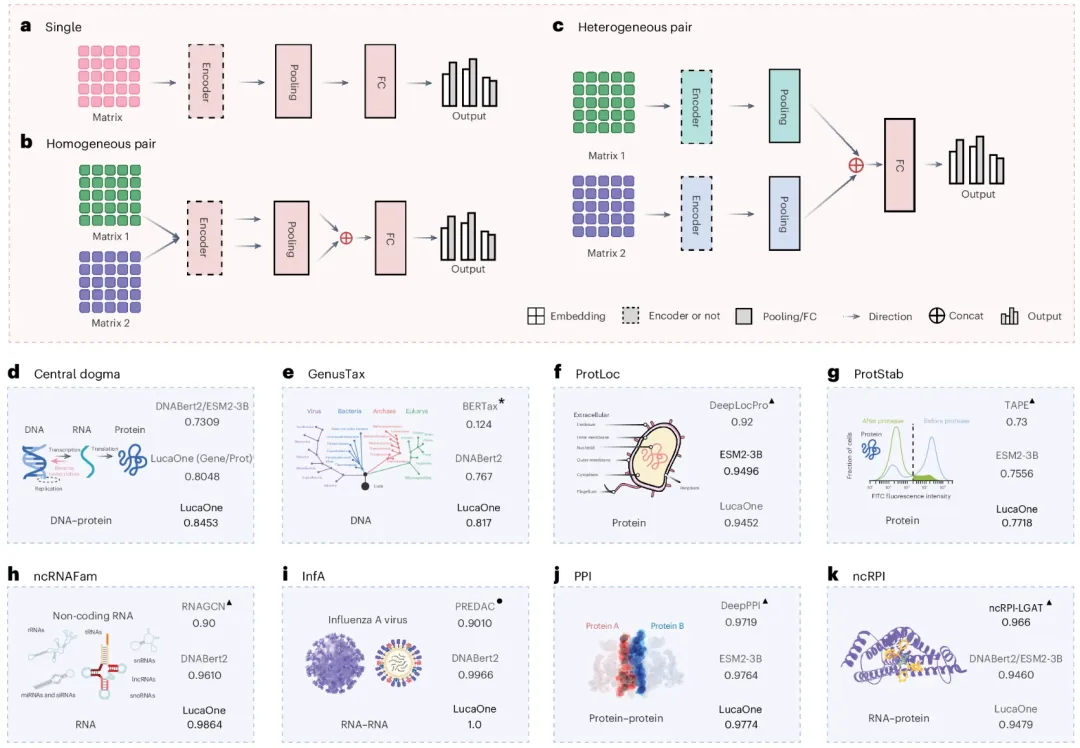
图示:具有三种输入类型的下游任务网络和八个验证任务的结果比较。(来源:论文)
在后续的验证测试中,LucaOne 在中心法则学习任务上取得了显著成效,预测准确率达到 0.85,远优于其他计算方法。
当分析细分表现时发现,LucaOne 在处理具有特殊进化适应性的生物如海鞘(Ciona intestinalis )时,预测表现特别差。海鞘利用中心法则的具体规则-密码子偏好性,与其他生物明显不同。
研究人员表示,这种情况可以认为海鞘用的是一种中心法则语法「方言」。而这种「方言」在训练数据集里仅有 100 条,因此模型没有很好的学习到这种规则。这表明了生物世界的多样性与复杂性,也为模型未来的数据扩充和优化指明方向。
在另外广泛选取的 7 个任务里,LucaOne 则表现优异,尤其是在流感 H3N2 病毒的免疫逃逸风险预测任务中,LucaOne 结合简单感知机模型实现了 100% 的准确率,可以为这一类公共卫生的重要问题提供了有力的支持。
结语
在这里,LucaOne 不仅是一种通用工具的尝试,它在回答一个开放性的问题:什么是「生物系统」的语言?这种语言能否被建模?显然,答案正逐渐倾向于肯定,这与「中心法则」息息相关。不过,这个问题目前来看是没有止境的,生命的规律还有太多未知在等待我们去破译。LucaOne 是一个好的开端。
相信,随着更多数据、更丰富模态的加入,以及模型的持续升级,LucaOne 将更深入揭示生物系统的智能,推动 AI 在生物科学、疾病诊断、药物开发等领域的广泛应用。